1. 论文要解决的问题
这篇论文提出的算法叫 PlaNet(Deep Planning Network)。核心目标是:
只从像素图像观测中学习环境动力学,并在学习到的低维潜在空间中做在线规划,从而解决连续控制任务。
传统规划方法在已知动力学时很有效,但现实中通常不知道环境动力学。模型无关强化学习可以直接学习策略,但需要大量交互样本。PlaNet 走模型化路线:
- 从交互数据中学习一个 latent dynamics model。
- 用该模型预测未来 latent state 和 reward。
- 每个环境步用 CEM 在 latent space 中搜索动作序列。
- 执行动作序列的第一个动作,然后收到新观测后重新规划。
这使 PlaNet 在 DeepMind Control Suite 的像素输入任务上,用约 1000 个 episode 达到接近 D4PG 使用 100000 个 episode 的性能。
2. 问题建模:从 POMDP 到潜在状态空间
论文把环境建模为部分可观测马尔可夫决策过程(POMDP)。在时间步 :
- 隐状态:
- 图像观测:
- 连续动作:
- 标量奖励:

其中真实环境动力学写作:
智能体策略为:
目标是最大化期望累计奖励:
由于单张图像通常不能完整揭示环境状态,例如 cartpole 可能部分移出视野,PlaNet 不直接把图像当作 Markov state,而是学习一个从历史观测和动作推断 latent state 的模型。
3. PlaNet 总体算法
PlaNet 的训练循环包含两个阶段:模型拟合和数据收集。
伪代码

3.1 数据与模型初始化
先用随机策略收集少量 seed episodes。论文中默认:
- seed episodes:
S = 5 - 每收集一个新 episode 前,做
C = 100次模型更新 - 训练 batch size:
B = 50 - 序列 chunk 长度:
L = 50
3.2 模型拟合
从 replay dataset 中随机抽取序列片段:
用变分目标训练:
- transition model
- observation model
- reward model
- encoder / posterior model
3.3 在线规划收集数据
每个环境步:
- 用 encoder 根据历史 推断当前 latent belief。
- 用 CEM 在 latent space 中规划未来动作序列。
- 执行规划序列的第一个动作。
- 加入小的高斯探索噪声。
- 使用 action repeat 执行动作。
- 把 episode 加入数据集。
PlaNet 没有学习显式 policy network 或 value network。动作完全由当前模型和在线规划产生。
4. RSSM:Recurrent State Space Model
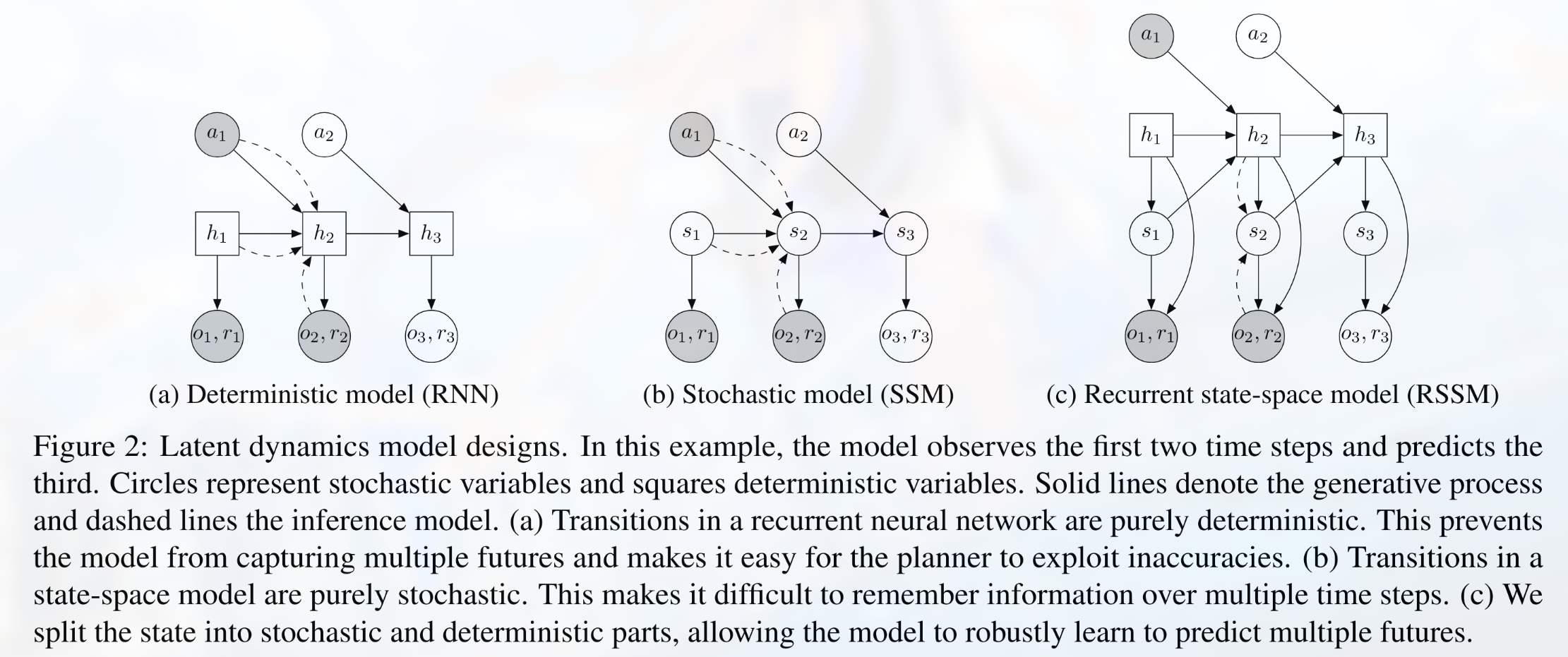
PlaNet 的关键模型是 RSSM,即 recurrent state-space model。它把 latent state 拆成两部分:
- 确定性隐藏状态
- 随机潜变量
模型定义为:
近似后验 / encoder 为:
其中 用 RNN/GRU 实现。论文使用 200 单元 GRU,随机 latent 是 30 维对角高斯分布。
4.1 为什么需要确定性状态
纯随机 state-space model 的问题是长程记忆困难。理论上,随机转移可以通过把方差学到很小来保存信息,但优化不一定会找到这个解。
RSSM 中的 deterministic path 类似记忆轨道,可以把过去信息稳定地传递到未来:
这对部分可观测场景很重要。例如 cartpole 的车可能暂时离开视野,模型仍需要记住它的位置和速度。
4.2 为什么需要随机状态
纯确定性 RNN 模型的问题是不能表达多种可能未来,而且规划器容易利用模型误差,找到在模型里高奖励但真实环境中无效的动作序列。
随机状态 的作用包括:
- 表达观测下的状态不确定性;
- 表达 partial observability 带来的多种未来可能;
- 给规划目标提供一定安全边界,减少过度自信预测;
- 避免确定性模型在未见区域被 CEM 过度利用。
论文消融实验显示,确定性和随机路径都重要;其中没有随机组件的确定性模型学习效果尤其差。
4.3 生成模型与推断模型的区别
训练时模型看到真实图像 ,可以用 encoder 得到后验:
规划时未来图像未知,模型只能从当前 latent belief 出发,用 prior 递推:
因此训练目标必须让 prior rollout 在多步预测中可靠,而不仅仅是重构当前图像。
5. 标准变分目标:一阶预测 ELBO
先看普通 latent sequence model。联合分布为:
近似后验为:
对观测似然:
用重要性加权改写:
由 Jensen 不等式:
得到 ELBO:
含义:
- 第一项是 reconstruction term,要求 latent state 能重构观测。
- 第二项是 complexity / KL term,要求 posterior 不要偏离 transition prior 太远。
论文还把 reward prediction 作为类似的重构项加入目标:
在实现中,观测模型和奖励模型都采用高斯似然。单位方差高斯的负 log-likelihood 等价于均方误差(差一个常数),因此训练目标可理解为:
论文使用 3 free nats,即把 KL loss 在低于 3 nats 的部分裁掉,避免 posterior 被过强压缩导致表示能力不足。
6. Latent Overshooting:多步预测目标
标准 ELBO 的主要问题是:transition prior 只被一阶预测直接训练。也就是说,KL 项只约束:
但规划时需要 rollout 多步:
如果模型容量有限,一步预测最优并不必然意味着多步 rollout 最优。很小的一步误差会在长期 rollout 中累积。
6.1 D-step Prediction
论文定义从 到 的 d 步预测:
也可以写成递归形式:
这里省略了动作条件,实际每个转移都条件在对应动作上。
当 d = 1 时,它退化为标准一阶 transition。
6.2 D-step Predictive Distribution 的变分下界
论文对 d-step predictive distribution 构造类似 ELBO:
直观解释:
- posterior 是看到真实观测后的 informed belief;
- multi-step prior 是从更早 latent state 开始,连续用 transition model rollout 得到的 belief;
- latent overshooting 让 rollout 多步后的 prior 去接近真实 posterior。
这比 observation overshooting 更便宜。Observation overshooting 会把每个多步预测都 decode 成图像,再算重构损失;在像素任务上很贵。Latent overshooting 只在 latent space 里做 KL:
因此计算量低得多,也更适合高维图像输入。
6.3 最终 Latent Overshooting 目标
为了训练所有距离 的预测,论文把多个 d-step bound 平均:
对应目标可写为:
其中期望中的 来自从 开始的多步 rollout。 类似 -VAE 中的 KL 权重,用来控制不同预测距离的正则强度。
实现上,论文对 的 posterior 停止梯度:
- multi-step prior 被训练去接近 posterior;
- posterior 本身不被 overshooting loss 反向拖动。
6.4 数学意义
Latent overshooting 约束的是一致性:
如果模型完美,一步转移反复应用得到的多步分布应该与直接看到未来观测推断出的 posterior 一致。有限容量模型做不到完美,因此这个目标把优化压力直接施加在规划真正需要的多步 rollout 上。
论文还用数据处理不等式说明,对于 Markov latent sequence:
从而有:
因此多步预测分布在期望上比一步预测分布更难优化。训练多步下界可以看作更强的 regularizer。
需要注意:最终最佳 PlaNet RSSM 在论文实验中并不依赖 latent overshooting;附录显示 overshooting 对 DRNN 等模型有明显提升,但对 RSSM 略有负面影响。
7. Latent Space Planning:CEM + MPC
PlaNet 规划时不生成图像,只在 latent space 中 rollout,并用 reward model 评分。

7.1 CEM 动作序列搜索
设规划 horizon 为 。在当前时间 ,PlaNet 搜索动作序列:
初始化一个因子化高斯分布:
每轮 CEM:
- 采样 个候选动作序列。
- 对每个动作序列,从当前 latent belief 出发 rollout:
- 用 reward model 计算候选序列分数:
- 选择分数最高的 个动作序列。
- 用这 个 elite samples 重新估计高斯均值和方差:
- 重复 轮。
- 返回当前步动作均值 。
论文默认 CEM 参数:
- horizon:
H = 12 - optimization iterations:
I = 10 - candidates per iteration:
J = 1000 - elite candidates:
K = 100
7.2 MPC:每步重新规划
PlaNet 只执行规划序列的第一个动作。下一个环境步收到新观测后,重新推断当前 latent state 并重新规划。这就是 model-predictive control。
这样做有两个好处:
- 用真实新观测修正模型 rollout 的误差;
- 不必承诺长动作序列,降低模型误差累积的风险。
7.3 为什么 Latent Planning 快
如果每个候选动作序列都生成未来图像,计算会很贵。PlaNet 的 reward model 直接从 latent state 预测奖励:
因此规划只需要:
不需要 decode 图像。这是 PlaNet 能在每个环境步评估上千个动作序列的关键。
8. 实验设计
8.1 任务
论文在 DeepMind Control Suite 的 6 个像素输入连续控制任务上评估:
| 任务 | 挑战 |
|---|---|
| Cartpole Swing Up | 固定摄像机,cart 可能移出视野,需要长程记忆 |
| Reacher Easy | 稀疏奖励,手臂和目标区域重合才有奖励 |
| Cheetah Run | 状态/动作维度较大,有接触动力学 |
| Finger Spin | 手指和物体接触,接触动力学明显 |
| Cup Catch | 稀疏奖励,只有接住球才有奖励 |
| Walker Walk | 需要先站起来再行走,倒地与地面碰撞难预测 |
所有任务输入都是第三人称图像:64 x 64 x 3 pixels
8.2 主要对比对象
论文比较了:
- A3C:model-free,使用 proprioceptive state,训练 100000 episodes。
- D4PG:model-free,使用 pixels,训练 100000 episodes。
- PlaNet:model-based,使用 pixels,训练 1000 episodes。
- CEM + true simulator:使用真实 simulator state 和真实动力学做 CEM,作为近似性能上界。
还做了多组消融:
- RSSM vs 纯确定性 GRU vs 纯随机 SSM;
- PlaNet online collection vs random collection;
- CEM iterative search vs random shooting;
- 单任务 agent vs 单个多任务 agent;
- latent overshooting 开/关;
- ReLU vs ELU;
- CEM 参数敏感性。
8.3 训练配置
论文默认超参数:
| 配置 | 值 |
|---|---|
| Deterministic path | GRU, 200 units |
| Stochastic latent | 30-dimensional diagonal Gaussian |
| MLP hidden layers | 2 layers, 200 units |
| Optimizer | Adam |
| Learning rate | 1e-3 |
| Adam epsilon | 1e-4 |
| Gradient clipping norm | 1000 |
| Batch size | 50 |
| Sequence length | 50 |
| Free nats | 3 |
| Seed episodes | 5 |
| Collect interval | 100 update steps |
| Exploration noise | Normal(0, 0.3) |
| CEM horizon | 12 |
| CEM iterations | 10 |
| CEM candidates | 1000 |
| CEM elites | 100 |
Action repeat 按任务设置:
| 任务 | Action repeat |
|---|---|
| Cartpole | 8 |
| Reacher | 4 |
| Cheetah | 4 |
| Finger | 2 |
| Cup | 4 |
| Walker | 2 |
作者指出敏感超参数主要是 action repeat、KL 权重 和 learning rate。
9. 实验结果
9.1 与 Model-free 方法比较
论文表 1 的最终性能如下:
| Method | Modality | Episodes | Cartpole Swing Up | Reacher Easy | Cheetah Run | Finger Spin | Cup Catch | Walker Walk |
|---|---|---|---|---|---|---|---|---|
| A3C | proprioceptive | 100000 | 558 | 285 | 214 | 129 | 105 | 311 |
| D4PG | pixels | 100000 | 862 | 967 | 524 | 985 | 980 | 968 |
| PlaNet | pixels | 1000 | 821 | 832 | 662 | 700 | 930 | 951 |
| CEM + true simulator | simulator state | 0 | 850 | 964 | 656 | 825 | 993 | 994 |
数据效率提升(PlaNet 相对 D4PG 达到相同最终性能所需 episode 数估计):
| 任务 | PlaNet over D4PG data efficiency gain |
|---|---|
| Cartpole | 250x |
| Reacher | 40x |
| Cheetah | 500x+ |
| Finger | 300x |
| Cup | 100x |
| Walker | 90x |
关键观察:
- PlaNet 在 100 episodes 内超过 A3C 在 100000 episodes 后的性能。
- PlaNet 在 500 episodes 后接近 D4PG 的最终性能,Finger 除外。
- 在 Cheetah Run 上,PlaNet 最终分数 662,高于 D4PG 的 524,相对提升约 26%。
- 在 Cup 和 Walker 上,PlaNet 接近 D4PG。
- 在 Reacher 和 Finger 上,PlaNet 明显低于 D4PG。
- CEM + true simulator 不是所有任务都超过 PlaNet,例如 Cheetah 上 CEM true simulator 为 656,而 PlaNet 为 662。这说明 CEM 规划本身不是绝对上界,也可能受 horizon 和搜索设置限制。
9.2 模型结构消融:RSSM Vs GRU Vs SSM
论文比较了:
- PlaNet RSSM:确定性 + 随机 latent;
- Deterministic GRU:纯确定性;
- Stochastic SSM:纯随机 state-space model。
结论:
- RSSM 在所有任务上整体最好。
- 确定性路径对长程记忆关键。
- 随机路径对规划尤其关键;没有随机组件时,agent 很难学好。
- 纯随机 SSM 也受限,因为跨多个时间步记忆信息困难。
这支持了 RSSM 的设计:确定性路径负责记忆,随机路径负责不确定性和多未来建模。
9.3 Agent 设计消融:online Collection 与 CEM
论文比较:
- PlaNet:用当前模型规划收集新数据;
- Random collection:始终用随机动作收集数据;
- Random shooting:每步随机采样 1000 个动作序列,选最优,不做 CEM 迭代 refinement。
结论:
- Online data collection 对所有任务都有帮助;
- 在 Cartpole、Finger、Walker 上尤其必要;
- CEM 迭代优化明显优于一次性 random shooting;
- 这说明 PlaNet 的样本效率不仅来自模型学习,也来自主动收集当前策略相关的数据。
9.4 多任务实验
作者训练一个单一 PlaNet agent 同时处理 6 个任务:
- agent 不知道当前是哪一个任务;
- 需要从图像中推断任务;
- 不同任务 action space 通过 padding 对齐;
- 每个 collect interval 收集每个任务一个 episode。
结果:
- 单一 agent 可以解决所有任务;
- 学习速度比每个任务单独训练慢;
- 说明共享 latent dynamics 对多任务控制有潜力,但还不是无损迁移。
9.5 Latent Overshooting 实验
附录实验比较标准变分目标和 latent overshooting:
- 对 RSSM:latent overshooting 略微降低性能;
- 对 DRNN 等其他模型:latent overshooting 可以显著提升性能。
因此,latent overshooting 是一个有价值的通用正则项,但论文最终 PlaNet 的强性能主要来自 RSSM + latent planning,而不是 overshooting 本身。
9.6 激活函数实验
论文比较 ReLU 和 ELU:
- 对纯随机 SSM 和纯确定性模型,ELU 有帮助;
- RSSM 对 ReLU/ELU 比较鲁棒。
这从侧面说明 RSSM 架构本身缓解了部分优化难题。
9.7 视频预测与 Latent Diagnostics
附录显示:
- RSSM 在 Cheetah 环境中可以做长达 50 步的 open-loop 像素预测;
- 冻结 dynamics model 后,用小网络从 latent state 预测 simulator 的真实位置、速度和 reward,结果较准确;
- 这说明 RSSM latent space 捕捉了与控制相关的真实系统信息。
10. 算法创新点与优势
10.1 从像素到 Latent Planning 的完整纯 Model-based Agent
PlaNet 不依赖 policy network 或 value network,而是完全用 learned model + online planning 决策。这在像素输入、连续动作、接触动力学、稀疏奖励任务上比以往 latent planning 工作更强。
优势是数据效率高。论文报告平均约 200x episode efficiency gain,相比 model-free D4PG 用少两个数量级的交互数据达到相近性能。
10.2 RSSM 结构设计有效
RSSM 把 latent state 分解为 deterministic memory 和 stochastic state:
- 解决长期信息保留;
- 解决不确定性、多未来和 partial observability;
- 二者结合后适合 planning,而不是只适合 reconstruction。
这个设计后来也成为 Dreamer 系列世界模型方法的重要基础。
10.3 规划在 Latent Space 中完成
PlaNet 训练 observation model 是为了提供密集监督信号,但规划时不 decode 图像。这样把高维像素预测问题转化为低维 latent rollout 和 reward prediction:
这大幅降低了 CEM 评估候选动作序列的成本。
10.4 Latent Overshooting 提供了多步预测正则化框架
虽然最终 RSSM 不依赖它,latent overshooting 的想法仍然有贡献:
- 针对 planning 需要多步 rollout 的事实;
- 避免在像素空间做昂贵 overshooting;
- 可作为通用 latent sequence model 正则项;
- 从变分下界角度给出了合理推导。
10.5 MPC 降低模型误差累积风险
每步只执行第一个动作并重新规划,使 PlaNet 不需要完全相信长 horizon rollout。新观测会不断纠正 latent belief,这对 learned dynamics 尤其重要。
11. 不足与局限
11.1 有限规划 Horizon
PlaNet 只规划固定 horizon。超过 horizon 的奖励没有 value function 估计,因此长延迟奖励任务会困难。作者也在讨论中提到,可以学习 value function 来近似 horizon 外的累计回报。
11.2 CEM 计算量大
默认每个环境步:
10 iterations x 1000 candidates = 10000 action-sequence evaluations虽然 latent rollout 比像素 rollout 快,但在线规划仍然昂贵。相比 amortized policy,部署成本更高。
11.3 依赖手工 Action Repeat
Action repeat 对性能重要,而且不同任务使用不同值。这相当于人工设置时间抽象。论文也指出未来方向是学习 temporal abstraction。
11.4 重构图像可能浪费模型容量
PlaNet 用 image reconstruction 提供训练信号,但复杂真实世界图像中,很多像素细节与控制无关。模型可能把容量花在背景、纹理等无关信息上。作者也提到未来可以学习不依赖 reconstruction 的表示。
11.5 模型误差与规划器利用问题仍存在
CEM 会搜索高奖励动作序列。如果模型在分布外区域过于自信,规划器可能找到 exploit model error 的动作。RSSM 的随机性缓解了这个问题,但论文没有使用 ensemble uncertainty 或显式 pessimism。
11.6 高斯分布假设较简单
RSSM 的 latent prior/posterior 使用对角高斯,observation/reward likelihood 也较简单。这限制了复杂多模态不确定性的表达能力。对于更复杂环境,可能需要更强的分布建模。
11.7 Latent Overshooting 对最终模型并非正收益
论文把 latent overshooting 作为贡献之一,但附录显示它对最终 RSSM 略降性能。这说明:
- RSSM 架构本身已经足够强;
- overshooting 的权重、距离和优化细节可能较敏感;
- 该贡献更像通用正则思想,而不是 PlaNet 最终性能的核心来源。
11.8 实验仍主要是模拟环境
任务来自 DeepMind Control Suite,视觉相对干净,动力学可重复。论文没有验证真实机器人或高度复杂视觉环境中的鲁棒性。
12. 总结
PlaNet 的核心贡献可以浓缩为:
learn a recurrent stochastic latent dynamics model from pixels, then do online model-predictive control entirely in latent space.
算法上,它由三部分组成:
- RSSM:用 deterministic path 记忆历史,用 stochastic state 表达不确定性。
- Variational model learning:通过 image/reward reconstruction 和 KL 正则训练 latent dynamics。
- CEM latent planning:在 latent space 中搜索高奖励动作序列,每步重新规划。
从数学角度看,标准 ELBO 保证了一步 transition prior 与 posterior 的一致性;latent overshooting 进一步把这种一致性扩展到多步 rollout,使训练目标更贴近 planning 的实际需求。
从实验角度看,PlaNet 在像素输入连续控制任务上显著提高了样本效率,并通过消融证明 RSSM、在线数据收集和 CEM 迭代规划都是性能关键。它的主要短板是计算量、有限 horizon、对 action repeat 和超参数的敏感性,以及在复杂真实视觉场景中的未验证泛化能力。