TL;DR
提出 Explore-Execute Chain (E2C) 方法,将模型推理解耦为高信息量的 explore (探索) 和高确定性的 execute (执行) 过程,从而实现了极高效的 Test-Time Scaling 策略——只需采样多个低成本的规划草稿并优选其一进行执行,便能在 AIME’24 等高难度基准上以 <10% 的 Token 消耗达到甚至超越 Forest-of-Thought 的性能,同时通过仅微调规划层实现了极低成本的跨领域(如医疗)迁移。
训练过程:分两阶段,SFT 和 RL.
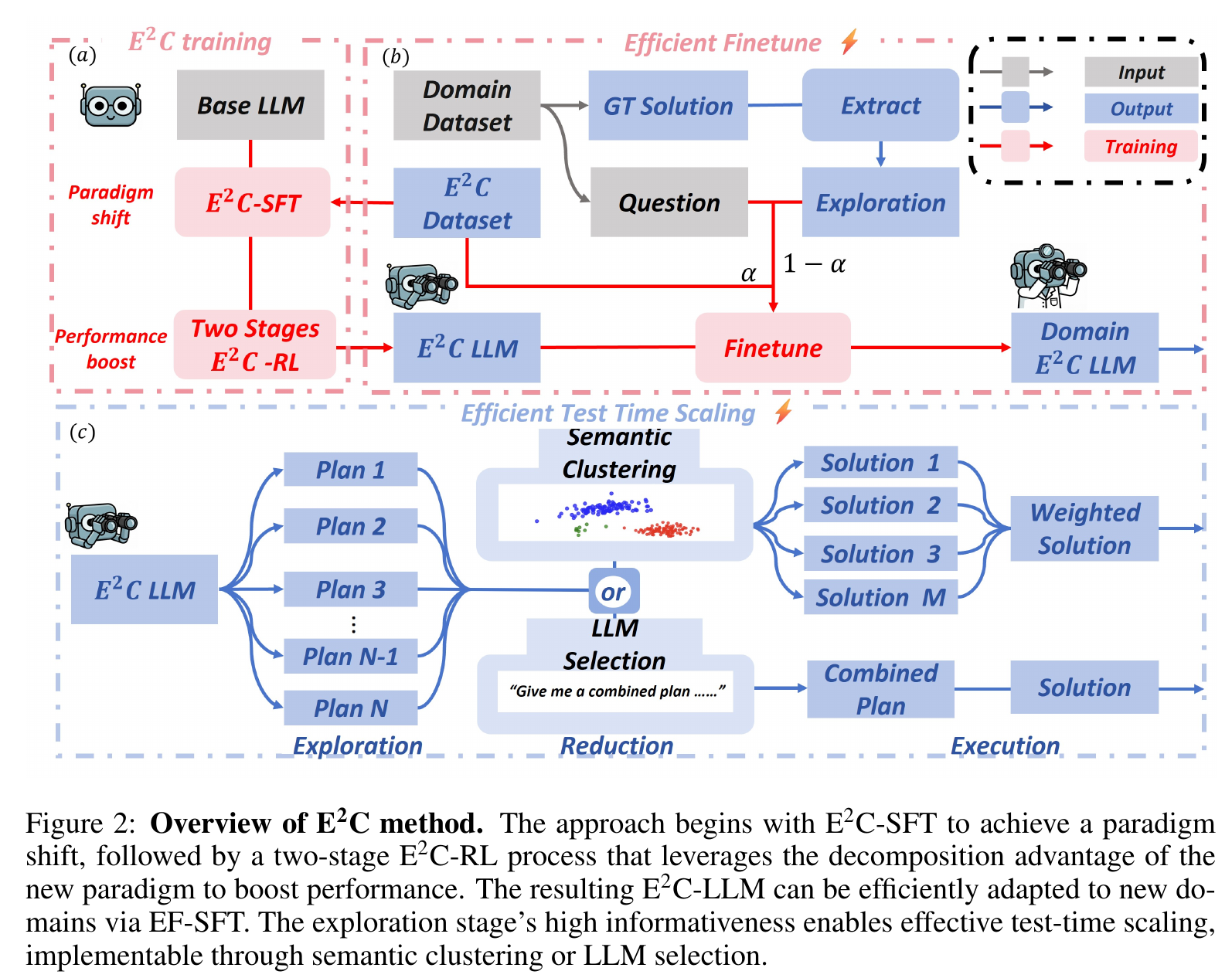
Stage 1: 合成数据并 SFT 训练。合成方式:对每个问题 ,先生成一段完整回答 ,然后将回答总结为概括性的步骤 ,然后再让模型根据 和 生成严格遵循步骤 的回答 . 这样就得到了一个数据对 . 所有合成数据的操作均在 base model 上进行
Stage 2: RL 训练. 在 explore 阶段,调高采样温度以增加多样性,并为每个 token 设置更高的权重,以迫使模型学会正确的 explore 方式. 奖励函数设置为 answer + format (= length + instruction) (检查是否严格按照 explore 中的步骤进行 execute)
推理:
- 每个问题 ,采样 个 plan
- 选择最好的 plan
- 方法一(Self LM-Judge):让模型自己看这 32 个 Plan,选一个逻辑最通顺的
- 方法二(Semantic Clustering):把 32 个 Plan 通过一个预先训练好的 encoder 得到 sentence 向量后进行聚类,找出最具代表性的(Centroid)进行 execute 过程,或者加权投票
- 使用选出來的 plan 进行 execute

领域迁移: 仅针对 explore 阶段进行微调,保留 execute 阶段的高确定性
疑问
- 先规划再执行的范式是否有问题。设想人类在解题时,只有对已经充分了解的任务才能够想出一个比较完善的规划思路,然后逐步执行;对于有一些了解的,往往会先规划几步,然后执行,看执行结果之后再决定接下来的规划;对于压根不了解的任务,则是会走一步看一步。那么对于这种先规划然后执行的范式,在训练完成之后对在其能力边界的问题的解决能力到底怎么样,有待讨论。
- 文中提出的缓解方法:先 rollout 32 个短 token 数的 explore,然后选择最 promising 的,再进行 execute
- 如何评判 plan 的粒度,模型会不会在 plan 阶段就生成了足够详细的步骤,导致 execute 阶段只会执行很少的推理
- 计算开销。当生成 个 plan 后,不管是用聚类或者是 LLM-as-Judge,都会有比较高的代价(前者相对较低但是准确度更低)
- reward hacking. 对于指令奖励 ,如果模型学会在 execute 阶段复述 plan 阶段,那么很可能会 hacking 正则表达式
- plan 多样性。经过训练后,模型可能会收敛到相似的 plan 上,这样后续的筛选就没有意义了。
- RL 阶段的奖励的设计无法鼓励模型保持 plan 阶段的高信息性和 execute 阶段的高确定性,只能通过 SFT 和 prompt,会不会太 weak 了