TL;DR
本文提出了 Group-in-Group Policy Optimization (GiGPO),一种专为长视界(long-horizon)多轮交互 LLM 智能体设计的无 Critic 强化学习算法,旨在解决现有 Group-based RL(如 GRPO)在稀疏奖励场景下难以进行细粒度信用分配(credit assignment)的难题。GiGPO 采用了一种层次化的双层优势估计架构:在 Episode 层级,基于完整的轨迹组计算宏观相对优势以捕捉全局任务完成质量;在 Step 层级,引入创新的锚点状态分组(anchor state grouping)机制,通过回溯识别跨轨迹的相同环境状态,将同一状态下衍生的不同动作聚合以计算微观相对优势。这种设计在无需额外 Rollout 或辅助价值模型的前提下,成功实现了精确的每步信用分配,实验证明 GiGPO 在保持与 GRPO 相同的显存开销和训练效率的同时,在 ALFWorld、WebShop 及搜索增强 QA 等复杂基准任务上显著优于 PPO 和现有 Group-based 方法。

方法
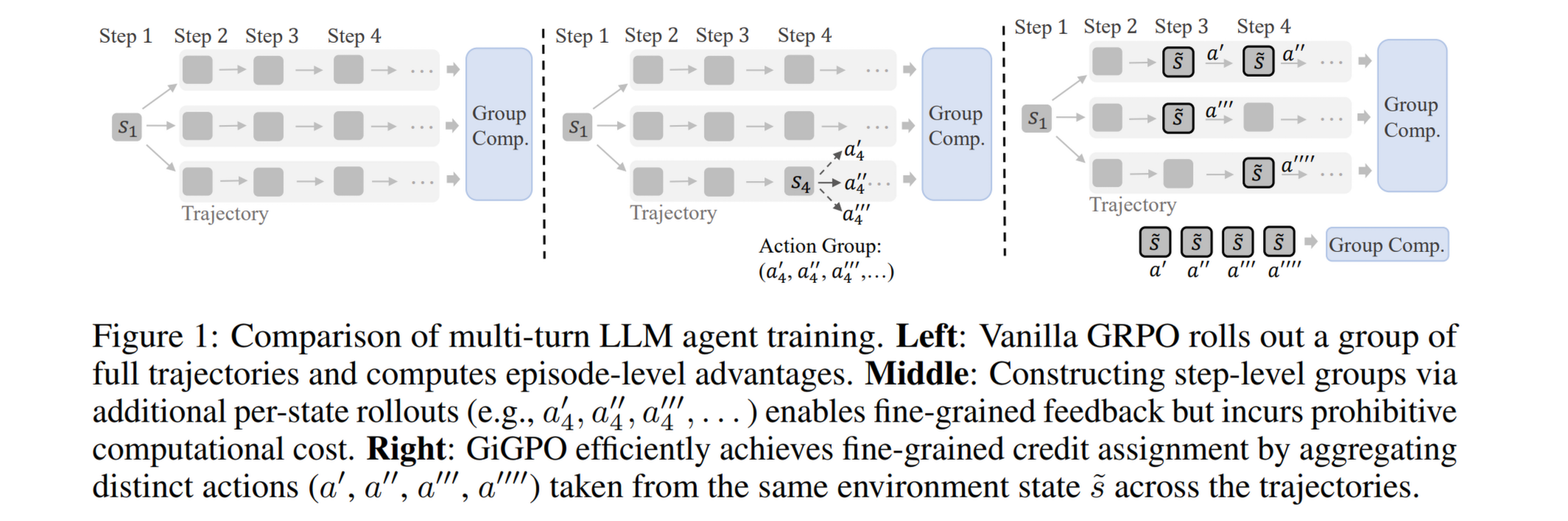
在训练 Agent 时,往往需要 Agent 和环境进行多轮交互,交互轨迹长达几十上百 k。而 GRPO 对同一条轨迹中的所有 token 一视同仁,导致优化难度较大,因此需要对 token 进行更精细的信用分配。GiGPO 就是为了缓解这个问题而提出的。
当环境初始条件一致并且策略不成熟时,LLM agent 会经常重复访问相同的状态,将这些状态作为一种“锚点”,称之为 anchor state。可以自然地在 rollout 后手动聚合这些重复出现的相同状态(但不同的输出 action)构成 step-level group。这让“同一状态下进行不同动作的优劣比较”成为可能。
奖励函数由两部分组成:
- Episode-level advantage. 和 GRPO 的 reward 相同
- Step-level Advantage. 利用上面提到的 anchor state 构建“环境 - 动作 - 最终奖励”组,然后相同环境计算 group-level 的 adv,得到新的 Advantage.
最后将这两部分加权相加即可,文中取权重为 1:1。
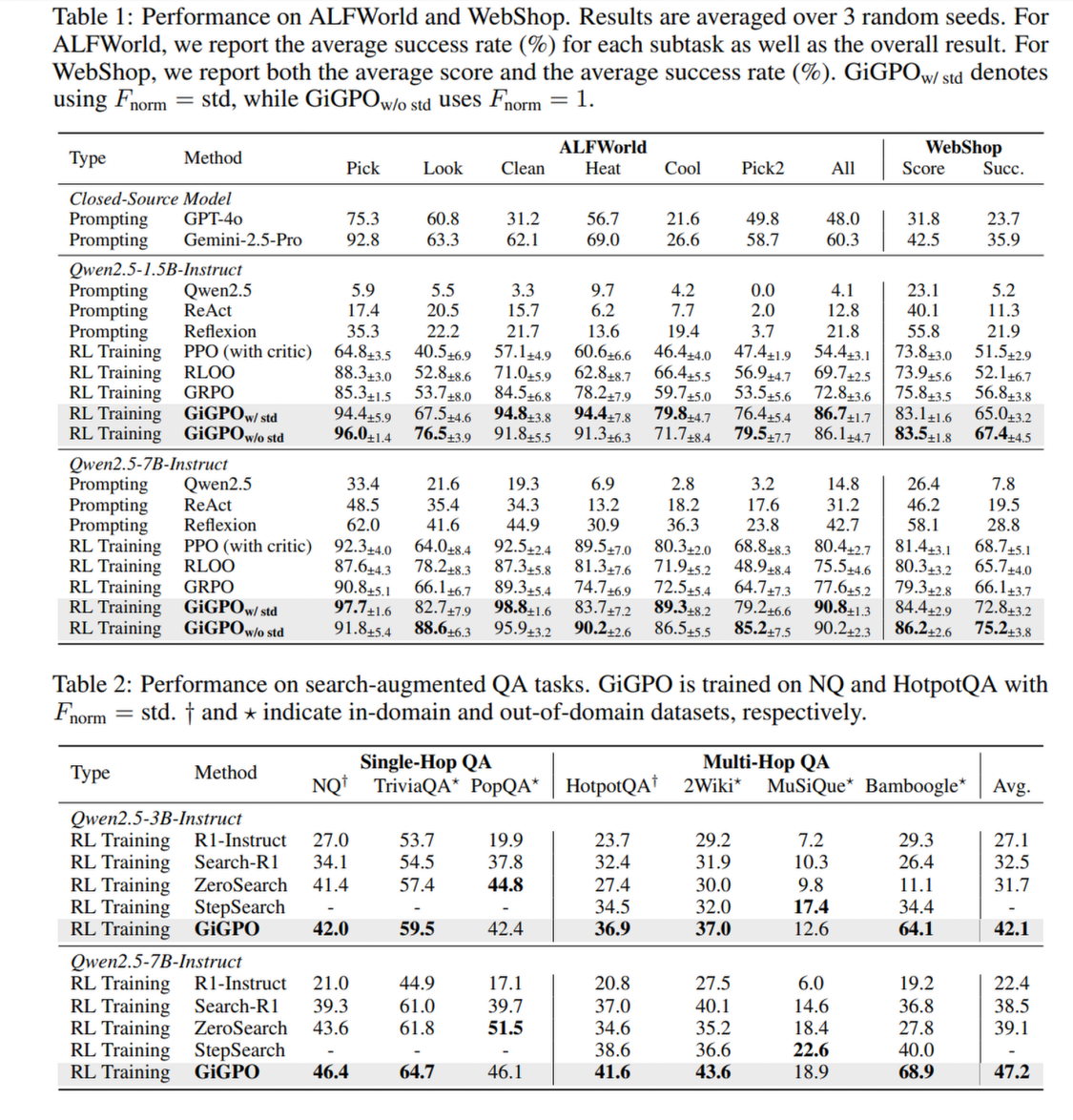
实验结果