TL;DR
这篇文章深入剖析了强化学习(RL)提升大模型推理能力的内在机理,发现其并非单纯的概率优化,而是一个层级化的双阶段过程:模型首先快速固化低层的计算与格式等执行技能,随后才进入真正的瓶颈期——探索高层的战略规划(如反思、回溯)。基于此发现,作者指出了现有算法(如 GRPO)对所有 Token 平均分配奖励的低效性,并提出了 HICRA(层级感知信用分配) 算法。HICRA 通过自动识别承载逻辑转折的**“规划 Token”**(如“Let’s try”、“Alternatively”)并定向放大其奖惩信号,引导模型集中火力攻克逻辑难点,从而在数学和多模态推理任务中取得了显著优于现有基准的性能,同时也为“思维链越长效果越好”等现象提供了信服的理论解释。
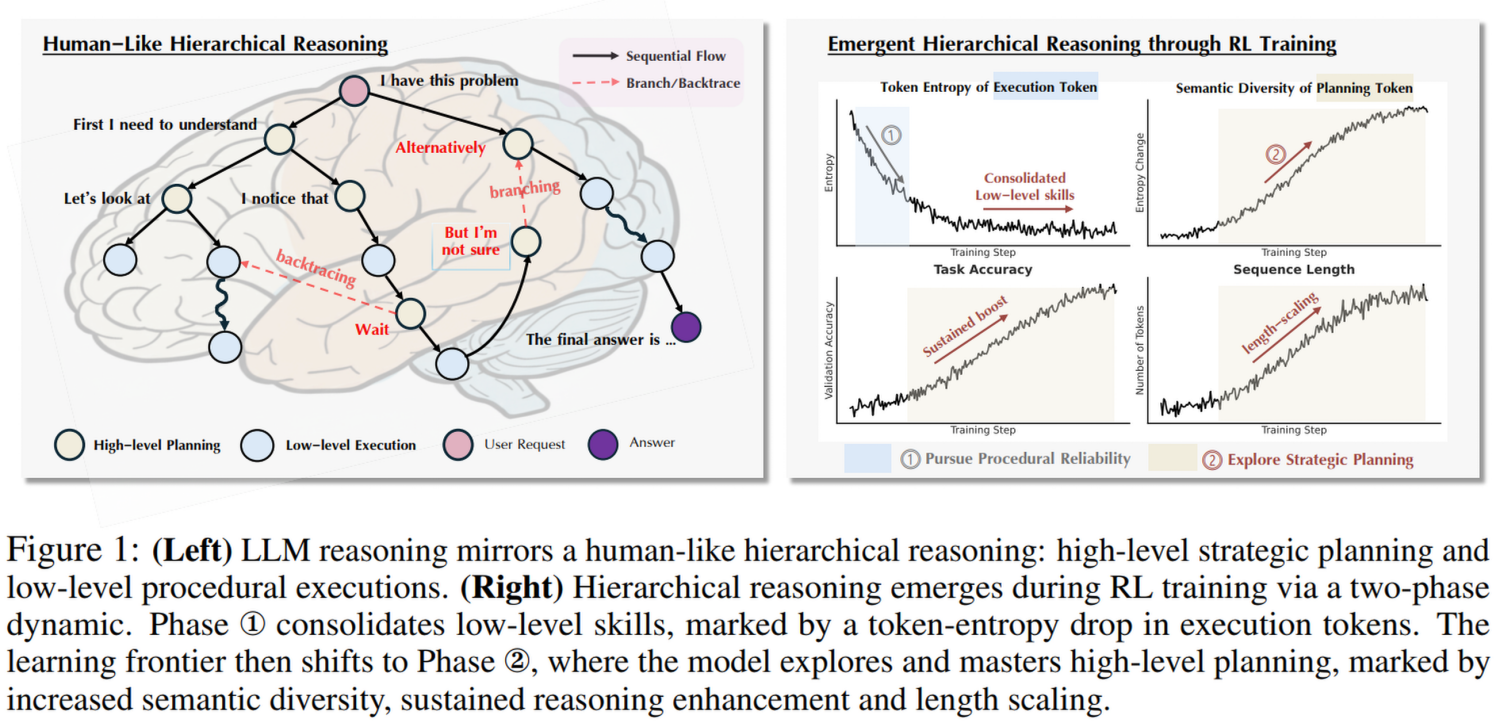
1. 核心洞察(Core Insight):推理能力的层级化涌现
论文首先提出了一个根本性问题:RL(如 PPO 或 GRPO)确实能提升模型的推理能力(如 DeepSeek R1、OpenAI o1),但到底发生了什么?
作者通过分析训练动态,发现 RL 并非单纯地“教会”模型推理,而是激发了模型预训练中潜藏的层级化结构。这种结构类似于人类的认知模型(系统 1 vs 系统 2):
- 高层规划(High-level Planning): 战略性的逻辑跳转,例如“让我们换个思路”、“假设…”、“但这可能不对”。
- 低层执行(Low-level Execution): 具体的计算、公式套用、变量代换等机械性步骤。
1.1 两阶段学习动态(Two-Phase Dynamics)
论文通过大量的实验观察(涵盖 Qwen、Llama 等模型),发现 RL 训练过程呈现出明显的两个阶段:
- 第一阶段:程序性巩固(Procedural Consolidation)
- 现象: 模型的执行 Token(如计算步骤)的困惑度(Perplexity)和熵(Entropy)急剧下降。
- 含义: 模型首先要学会“不犯低级错误”。它在通过 RL 的负反馈快速修正格式错误、计算错误。此时模型变得非常“自信”,不再在基础操作上犹豫。
- 结果: 这一阶段主要是为了获得程序正确性(Procedural Correctness)。
- 第二阶段:战略性探索(Strategic Exploration)
- 现象: 一旦低层技能稳固,执行 Token 的指标趋于平稳。此时,规划 Token(Planning Tokens)的语义熵(Semantic Entropy)开始上升。
- 含义: 真正的推理能力提升发生在这里。模型开始尝试不同的解题策略、自我反思(Self-reflection)、回溯(Backtracking)和多角度思考。
- 关联: 这一阶段直接对应了推理准确率的持续提升和长度外推(Length-scaling) 现象(即生成的思维链越长,效果越好)。
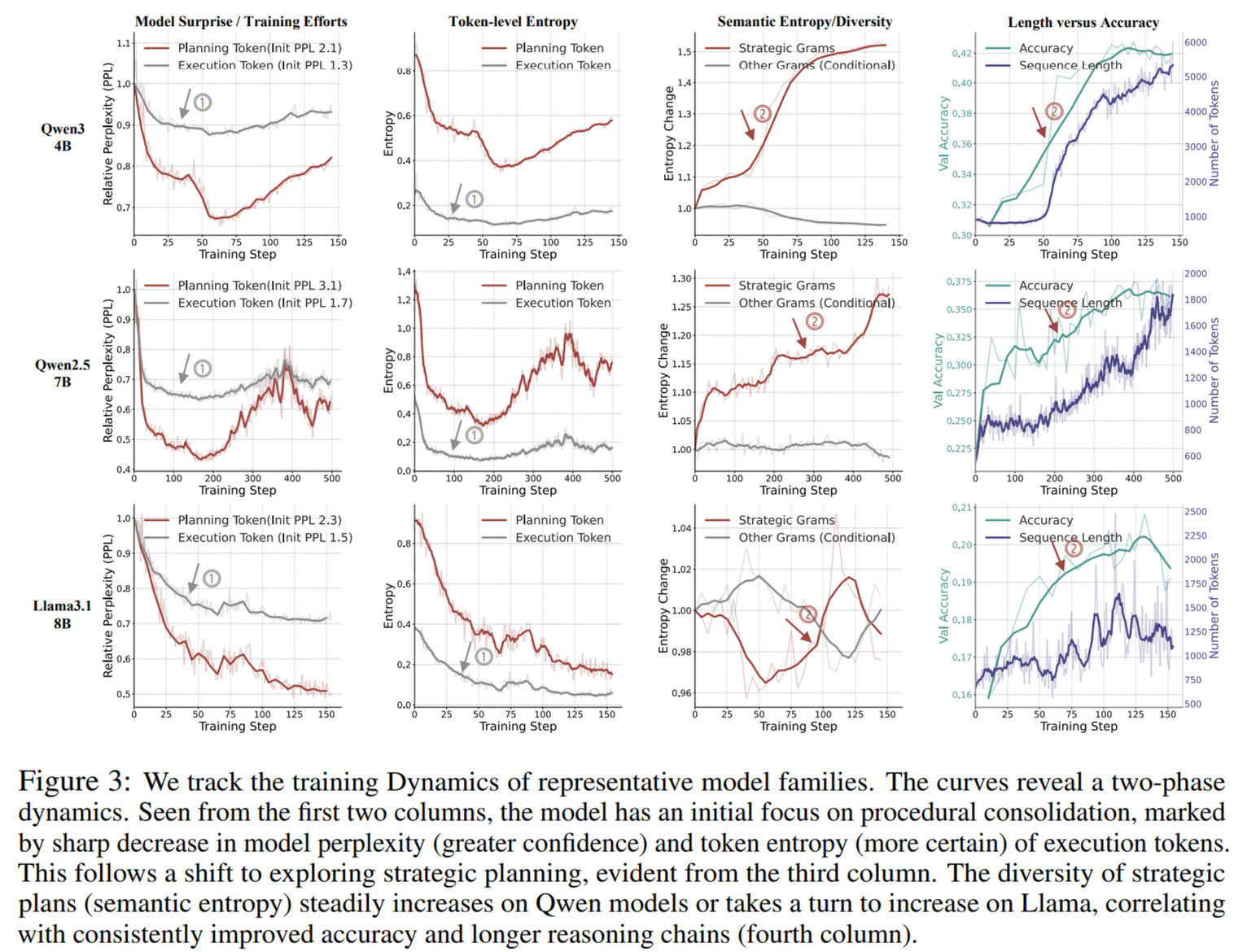
1.2 关键发现:Token 熵的误导性
以往研究常用“Token 级别的熵”来衡量模型的探索程度。但这篇论文指出这是误导性的。
- 因为绝大多数 Token 是低层执行 Token(占据了序列的大部分),它们随着训练变得越来越确定(熵降低)。
- 这就掩盖了高层规划 Token正在变得越来越多样化(熵升高)的事实。
- 结论: 模型虽然在“怎么算”上越来越确定,但在“怎么想”上却在进行更发散的探索。

2. 方法论:HICRA 算法
基于上述发现,作者指出了现有主流算法(如 GRPO)的低效之处:GRPO 对所有 Token 一视同仁地分配奖励/惩罚(Credit Assignment)。这稀释了优化压力,未能集中火力攻克真正的瓶颈——高层规划。
为此,作者提出了 HICRA (Hierarchy-Aware Credit Assignment),即层级感知信用分配。
2.1 识别规划 Token(Functional Proxy)
首先,如何定义哪些是“规划 Token”?作者没有使用昂贵的人工标注或 GPT-4 打分,而是提出了一种无监督的统计方法——Strategic Grams (SGs):
- 语义聚类: 从成功解题的语料中提取 n-gram,利用语义向量聚类(解决同义词问题,如 “Let’s try” 和 “Alternatively” 归为一类)。
- 频率识别: 筛选出那些“在很多不同题目中都出现”(通用性)但在“单个解题路径中较稀疏”(架构性)的短语。例如:“First I need to”, “Wait, checking the…”, “This implies that”.
2.2 算法公式
在 GRPO 的基础上,HICRA 修改了优势函数(Advantage Function)。
假设 是规划 Token 的集合, 是原始 GRPO 的优势值,HICRA 的修正如下:
- 直观解释:
- 如果一条路径是成功的(),HICRA 会额外奖励其中的规划 Token。
- 如果一条路径是失败的(),HICRA 会加重惩罚其中的规划 Token。
- 是放大系数(实验中设为 0.2)。
- 原理: 这通过重塑策略梯度,迫使模型将学习重点放在那些决定成败的关键决策点(Key Decision Points)上,而不是浪费在机械的计算步骤上。
3. 实验结果(Experiments)
作者在多个模型(纯文本模型和多模态模型)和多个基准测试上验证了 HICRA 的有效性。
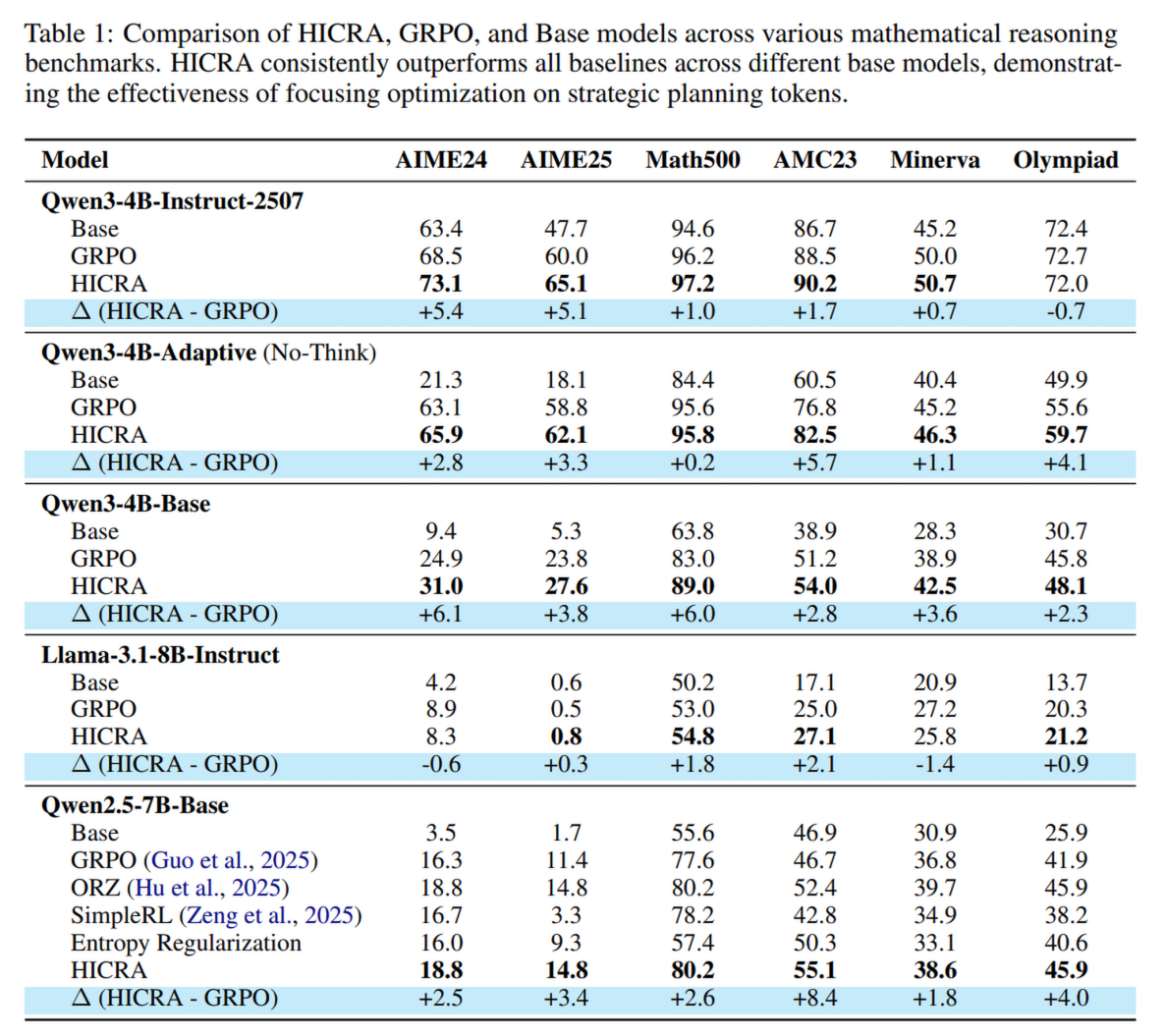
3.1 主要性能对比
HICRA 在所有测试中均一致性地优于基准模型(Base)和标准 RL 方法(GRPO)。
- 文本数学推理(Qwen3-4B-Instruct):
- 在极具挑战性的 AIME24 上,HICRA 比 GRPO 高出 5.4% (73.1% vs 68.5%)。
- 在 Math500 上达到 97.2%。
- 多模态推理(MiMO-VL, Qwen2.5-VL):
- 在 MathVista 和 MathVerse 上也取得了显著提升(例如 MiMO 在 MathVista 上提升 7.0%)。
3.2 错误类型分析
作者分析了模型失败的案例,发现:
- RL 训练主要减少的是 “规划与策略类错误” (Planning & Strategy Errors)。
- 相比之下,具体的执行类错误(如计算错误)虽然也有减少,但不是性能提升的主因。
- 这进一步证实了战略规划是推理能力的真正瓶颈。
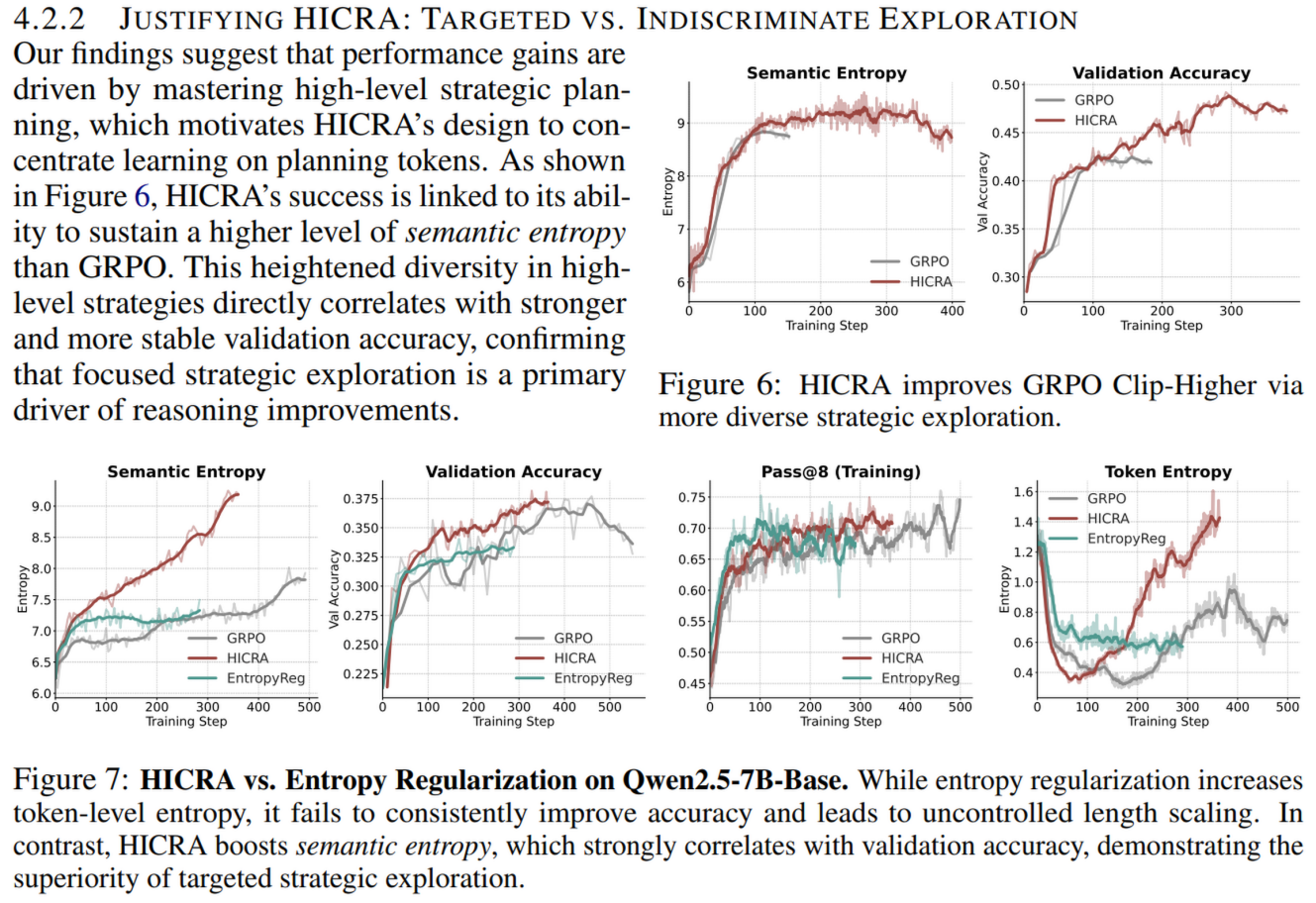
3.3 对比熵正则化(Entropy Regularization)
传统的鼓励探索的方法是增加熵正则项(让模型输出更随机)。实验表明:
- 熵正则化无效甚至有害: 它只能增加 Token 级别的熵(让废话变多),却不能提升准确率。
- HICRA 有效: 它提升了“语义熵”(Semantic Entropy),即策略的多样性,从而提升了准确率。
3.4 规划 Token vs. 高熵 Token(Fork Tokens)
近期有其他工作 1 提出用“高熵 Token”作为决策点的代理。作者对比发现:
- 不对称性: 规划 Token 通常是高熵的,但高熵 Token 不一定是规划 Token。
- 许多高熵 Token 仅仅是因为表达方式多样(例如“Consider” vs “Let’s consider”),并不承载逻辑转折。因此,HICRA 基于语义功能的定义比单纯基于统计熵的定义更精准

4. 解释主要现象(Explaining Phenomena)
HICRA 提出的层级推理视角完美解释了当前大模型 RL 训练中的几个“谜团”:
- Aha Moments(顿悟时刻): 这是模型在第二阶段突然“发现”并掌握了一种新的高效解题策略(如反思模式)的时刻。
- Length-Scaling(长度外推): 更高级的策略(规划、回溯、验证)自然需要更多的 Token 来描述。推理链变长是策略变复杂的副产物,而非单纯的“啰嗦就有用”。
- 熵的动态变化: 解释了为什么整体熵下降(因为执行变熟练),但能力却上升(因为规划变丰富)。
5. 局限性与未来工作(Limitations)
尽管 HICRA 表现出色,作者也坦诚地列出了局限性:
- 依赖程序性基础(Dependency on Procedural Foundation):
- HICRA 假设模型已经具备基本的低层执行能力(如会做加减法)。
- 失败案例: 在 Llama-3.1-Instruct 上,HICRA 表现不如 GRPO。原因在于该模型的基础计算能力较弱,在第一阶段(程序性巩固)没过关。如果在模型连基础计算都做不对的情况下强行奖励“规划”,反而会扰乱学习动态(图 14 展示了这一点)。
- Strategic Grams 的静态性: 目前的规划 Token 集合是基于语料预先挖掘的,虽然具有鲁棒性,但未能随训练动态实时更新。
- 通用性验证: 目前的实验主要集中在数学推理领域,代码生成(Coding)或 Agent 工具使用等领域的层级结构可能有所不同。
总结
这篇文章极大地深化了我们对 LLM + RL 如何工作的理解。它告诉我们:推理不仅仅是预测下一个词,而是高层规划与低层执行的交响曲。
- 理论上: 揭示了从“程序性巩固”到“战略性探索”的两阶段学习定律。
- 实践上: 提出了 HICRA,证明了 “好钢要用在刀刃上”——在 RL 中,应给予承载思考逻辑的规划 Token 更高的权重,而非平均用力。
这对未来设计更高效的 Reasoning 模型训练算法指明了方向:从关注 Token 层面的概率,转向关注语义层面的策略结构。
Meta-Learning 视角
直观一点来讲,论文中的 planning token 和其他 token 可以分别对应于流程图中的控制流节点和数据流节点。这篇论文的意思就是 base model 在已经有了数据流节点的能力之后,在 RL 训练阶段更应该來训练其“控制流节点”的能力。也可以看作是执行层(sub policy)和规划层(meta policy)之间的区别。
在 RL 训练初期,模型迅速学会了 sub-policy 的能力(导致初期的正确率迅速上升,同时大部分 token 的熵迅速下降);而在训练中后期,模型更应该关注 meta policy 的提升,即如何进行规划,在每一个“推理岔路口”应该如何抉择,也就是“学会如何推理”本身,而非“学会如何通过推理來解决当前问题”。在 HICRA 中,即为通过加权规划 Token,强制模型去学习这种通用的解题结构,而不是死记硬背具体的计算步骤。
从 token 和语义的角度來分析,HICRA 将训练的目标从 token 上转移到了语义上(推理逻辑上),即让模型“随机猜测单词”到“随机尝试策略”。总而言之,这篇文章证明了 LLM 的 RL 训练本质上是一个层级化的元策略优化过程。