TL;DR
本文提出一种名为 LAMER 的通用元强化学习(Meta-RL)框架,通过引入跨回目的训练机制与基于反思的上下文适配,解决了语言智能体在复杂长程任务中缺乏主动探索能力的问题;实验证明,LAMER 不仅在推箱子、扫雷及 Webshop 等任务上显著优于传统强化学习基线(性能提升 11-19%),更展现出卓越的测试时扩展性(Test-time Scaling)以及对未知困难任务的泛化能力。
一、核心创新点
LAMER 的核心贡献在于将 Meta-RL(元强化学习) 引入 LLM 智能体训练,其创新点体现在以下三个方面:
- 从单回目到多回目(Multi-episode)的范式转变:
- 传统的 RL 智能体训练通常针对单个回目(Episode)优化。而 LAMER 将“一个试验(Trial)”定义为包含 个回目的序列。
- 创新意义:这迫使模型在早期回目中通过“探索”获取信息,并在后期回目中进行“利用(Exploitation)”,从而学习到如何“学习”。
- 跨回目的信用分配(Cross-episode Credit Assignment):
- 引入了跨回目的折扣因子 ,将后期回目的奖励反馈给早期回目的动作。
- 创新意义:这种机制在数学上显式地激励了智能体在早期进行能够带来长期收益的探索行为。
- 基于自我反思(Self-reflection)的上下文内策略适配:
- LAMER 不依赖测试时的梯度更新,而是通过生成文本形式的“反思”来总结失败教训并修正策略。
- 创新意义:将反思过程作为 Meta-RL 的“内环(Inner-loop)”进行显式训练,使模型学会如何生成高质量的反思来指导后续尝试。
二、方法论(Methodology)
1. 跨回目训练框架
LAMER 将每个训练单元设为一个包含 个回目的序列 。
- 流程:如果第 个回目失败,智能体从相同初始状态开始第 个回目,但此时它拥有前 次尝试的记忆。
- 目标函数:最大化跨回目的累计折扣奖励 (见公式 4 和 5):
这里 调节探索与利用的平衡:较小的 偏向快速解决,较大的 鼓励早期探索。
最终目标函数为
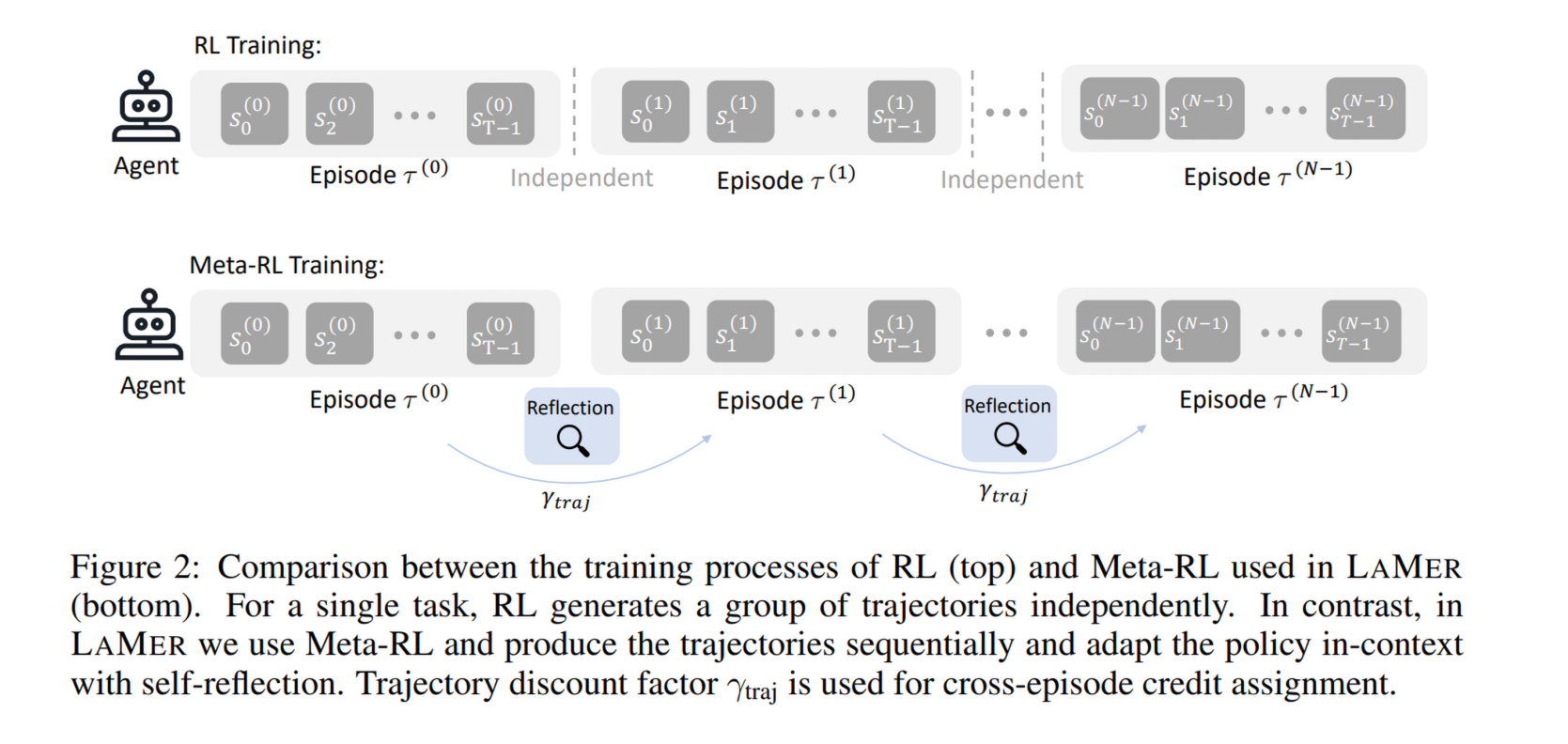
2. 上下文内适配与反思
在元学习语境下,适配过程是“内环”。LAMER 使用 跨回目记忆 :
- 内容:包含历史轨迹 和智能体生成的文本反思。
- 反思逻辑:每个回目结束后,提示智能体分析错误并制定新计划。这个反思步骤也是通过 RL 显式训练的,因为反思的好坏直接影响下一回目的奖励。
3. 优化算法
LAMER 具有通用性,兼容多种策略梯度算法。论文中默认使用 GiGPO(一种高效的智能体优化算法),也支持 PPO、GRPO 等。其梯度估计如公式(6)所示,通过跨回目优势函数 来更新模型参数 。
三、实验结果(Experimental Results)
研究团队在 Sokoban(推箱子)、MineSweeper(扫雷)、Webshop(购物) 和 ALFWorld(家居任务) 四个环境上进行了评估。
1. 性能大幅提升
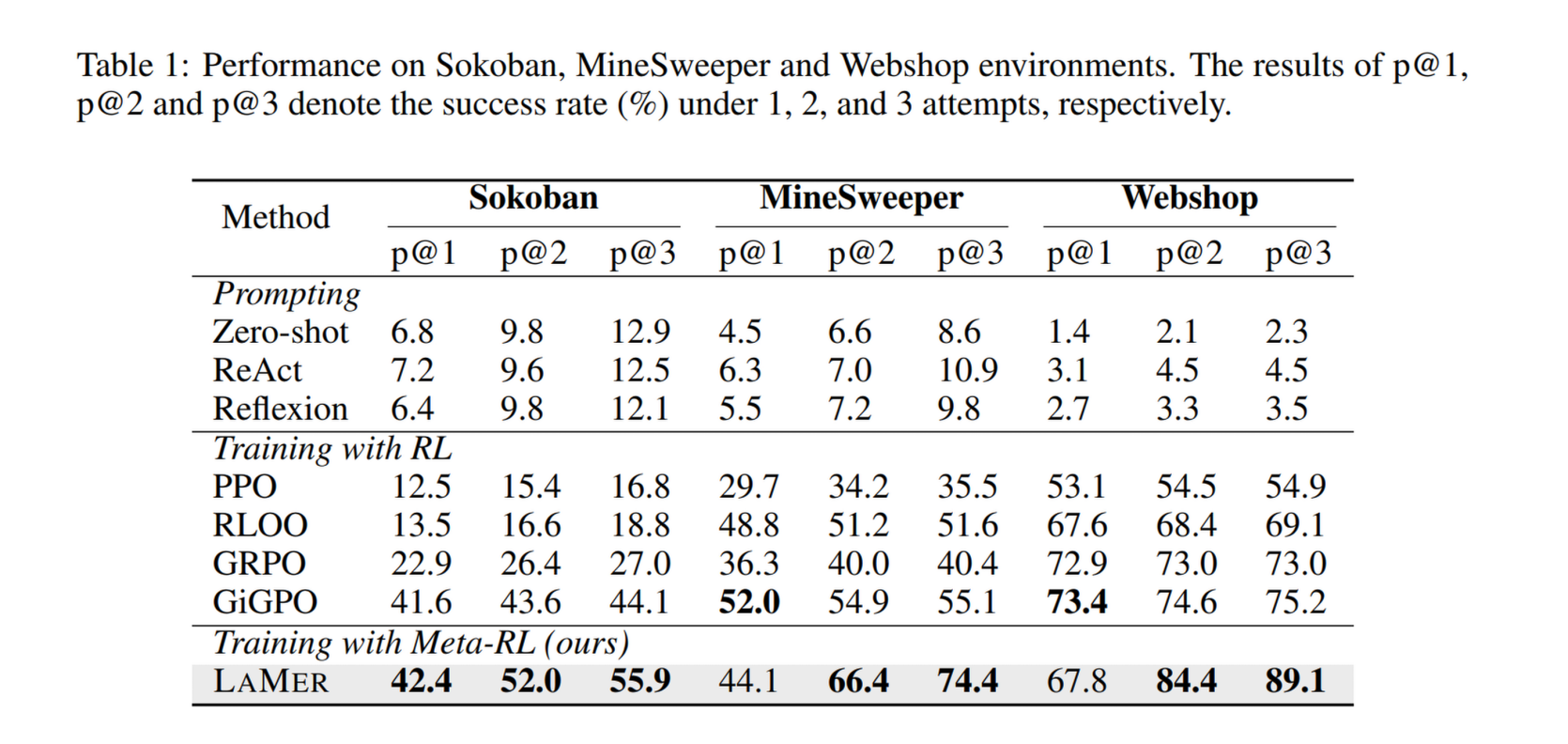
在 (pass@3,即三次尝试中的成功率)的设置下,LAMER 显著优于所有基线:
- Sokoban:LAMER 达到 55.9%,比最强的 RL 基线(GiGPO 44.1%)提升了 11.8%
- MineSweeper:LAMER 达到 74.4%,相比 GiGPO(55.1%)提升了 19.3%。
- Webshop:LAMER 达到 89.1%,相比 GiGPO(75.2%)提升了 13.9%。
2. 测试时缩放(Test-time Scaling)
LAMER 表现出极强的“从错误中恢复”的能力。
- 观察 Table 1:在 MineSweeper 中,LAMER 的 pass@1(44.1%)略低于 GiGPO(52.0%),但到了 pass@3,LAMER 飞跃至 74.4%,而 GiGPO 几乎没有提升(55.1%)。
- 结论:标准 RL 趋向于学习一种“死记硬背”的确定性策略,而 Meta-RL 训练出的 LAMER 学会了在第一次失败后如何通过探索和反思在后续尝试中获胜。
3. 泛化能力(Generalization)
- 更难的任务:在增加箱子数量或地雷数量的任务中,LAMER 的性能下降比标准 RL 慢得多(见 Figure 4),保持了稳定的领先差距。
- 未见任务(OOD):在 ALFWorld 的分布外测试(如从“Pick”泛化到“Cool”)中,LAMER 的性能提升尤为显著(Table 2),在某些任务上比 RL 基线高出 20% 以上。
四、深入分析(Analysis Details)
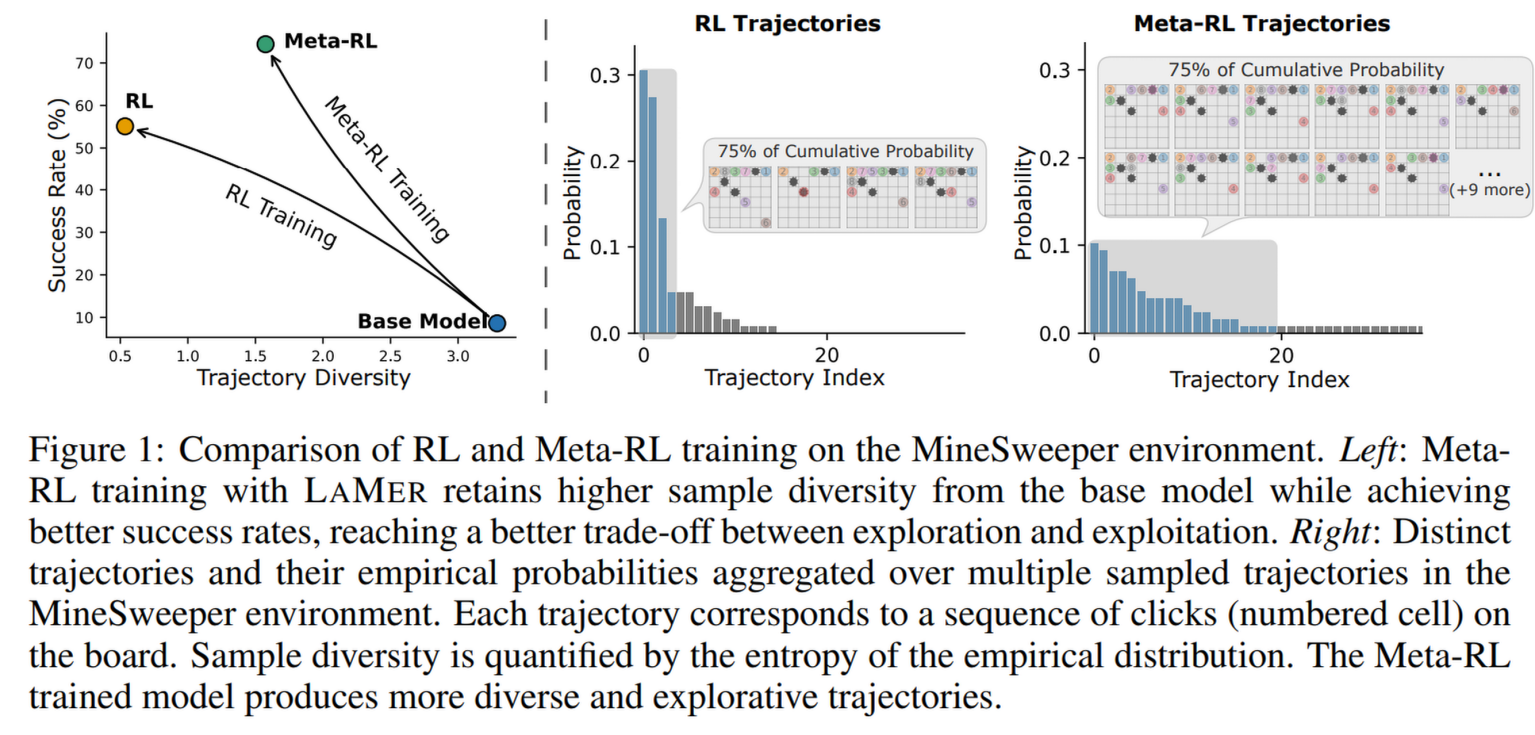
- 多样性与探索(Figure 1 & 3):
- 通过衡量轨迹熵(Trajectory Diversity)发现,标准 RL 训练后轨迹变得非常单一(确定性),而 LAMER 保留了接近原始模型的样本多样性。
- 这证明 Meta-RL 确实诱导了探索行为,避免了模型过早收敛到次优的单一路径上。
- 记忆配置消歧(Table 3):
- 消歧实验表明,“仅保留反思(Reflection-only)” 的效果竟然优于“轨迹 + 反思(Both)”。
- 原因:纯文本反思更简洁、聚焦,能为模型提供更明确的引导,减少了长轨迹带来的上下文噪声。
- 训练成本(Section 6.3):
- LAMER 的数据利用率极高。虽然由于回目间的依赖性,其采样过程不如标准 RL 那样可以完全并行化(训练耗时约为标准 RL 的 2 倍),但它不需要更多的轨迹总数就能达到更优的效果。
五、总结
LAMER 的成功证明了: LLM 智能体并不缺乏学习能力,而是缺乏鼓励探索的训练机制。通过 Meta-RL 框架,模型不仅学会了如何执行动作,更学会了如何从失败中提取信息并进行自我修正。
局限性与未来方向:
- 目前的回目内采样是串行的,未来可以探索异步采样提高效率。
- 可以尝试将 Meta-RL 与更强的推理模型(如带有内置思考链的模型)结合,进一步提升复杂决策的质量。