RL’s Razor: Why On-Policy Reinforcement Learning Forgets Less
TL;DR
研究表明,相较于监督微调,强化学习在保持新任务性能的同时,能显著更好地保留先验知识和能力,其遗忘程度取决于分布偏移,且强化学习倾向于选择与原始模型 KL 距离最小的解决方案。
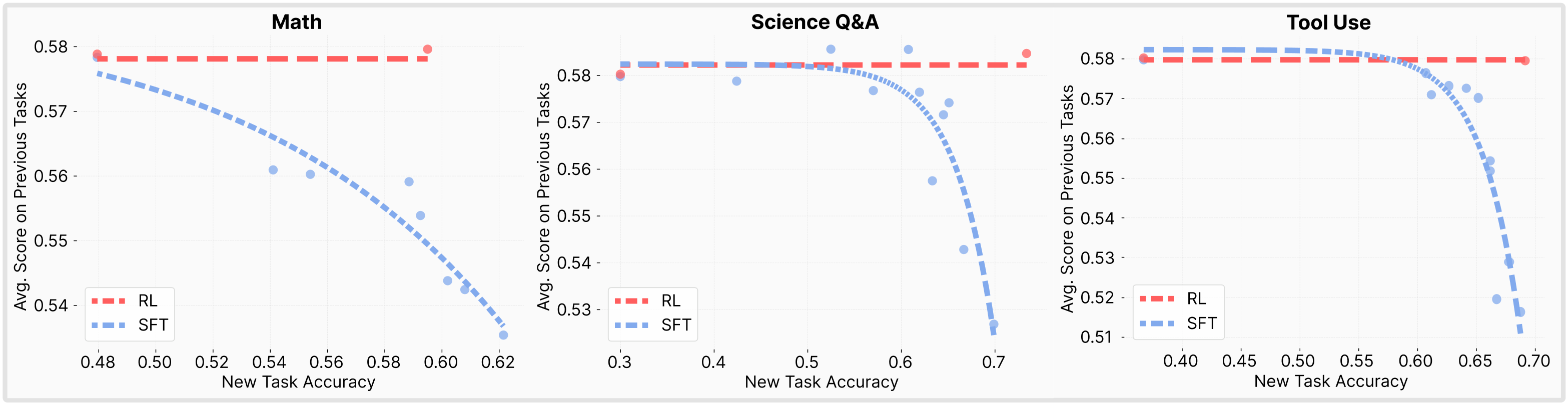
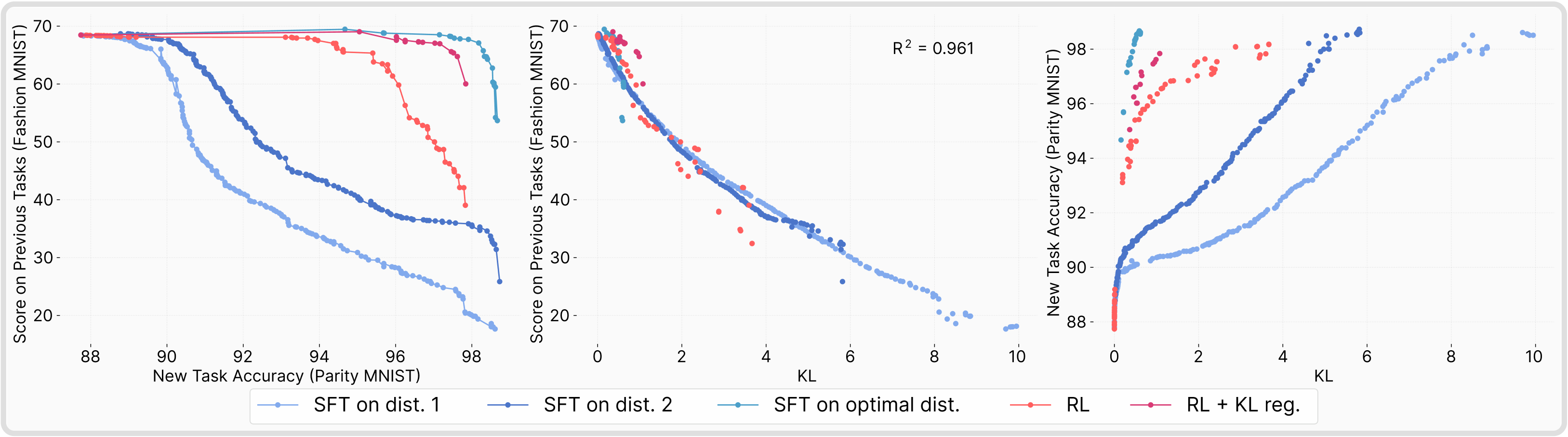
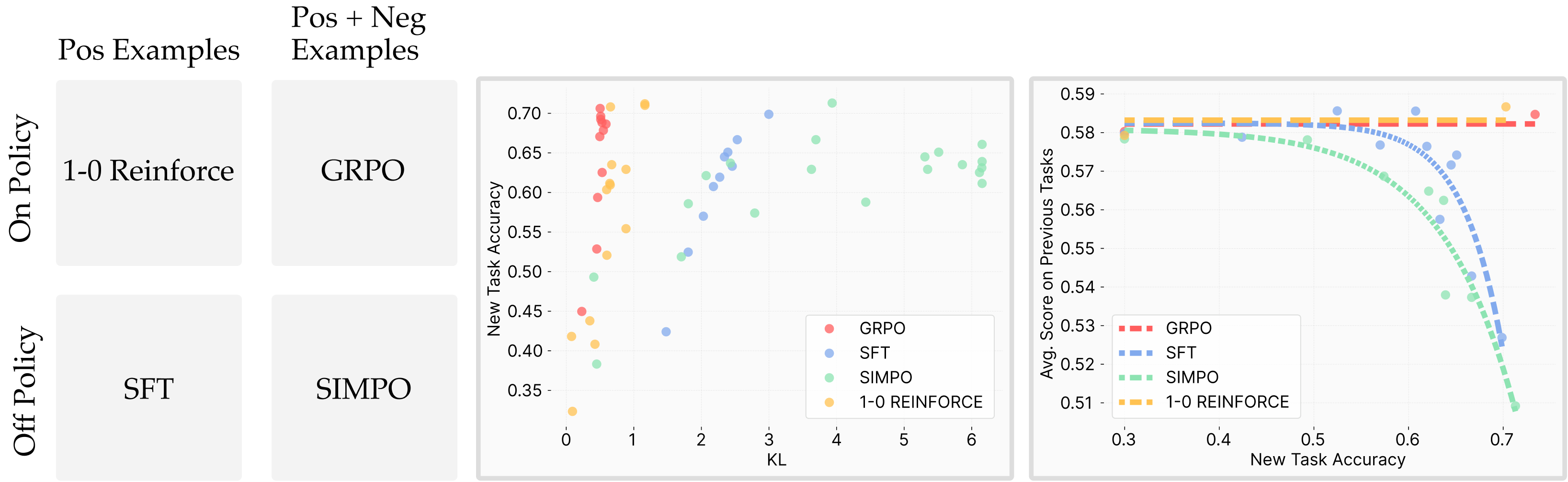
个人认为这篇文章只讲了一些显而易见的道理,并无很大参考价值,只是图比较好看,可以参考之处是对 KL 散度、分布偏移的一些实验验证,如下几图
RL’s Razor: Why On-Policy Reinforcement Learning Forgets Less
TL;DR
研究表明,相较于监督微调,强化学习在保持新任务性能的同时,能显著更好地保留先验知识和能力,其遗忘程度取决于分布偏移,且强化学习倾向于选择与原始模型 KL 距离最小的解决方案。
个人认为这篇文章只讲了一些显而易见的道理,并无很大参考价值,只是图比较好看,可以参考之处是对 KL 散度、分布偏移的一些实验验证,如下几图