在 CLIP 中使用 InfoNCE loss:
基于 softmax 的 loss 计算涉及到整个 batch,导致扩展 batch size 时会出现极大的计算负担,内存占用是 ;这里为了计算一对正样本 的 loss 就遍历了整个 batch
而 SigLIP 则将 loss 转化为一系列独立的二元分类问题:
其中 当且仅当 ,否则 。这里 和 都是可学习的。这里设置偏置项 是因为每个 batch 中正负样本的数量不均衡(),训练初期会严重偏向于将所有对都预测为负,原论文中设置 初始值为 10 来缓解这个问题
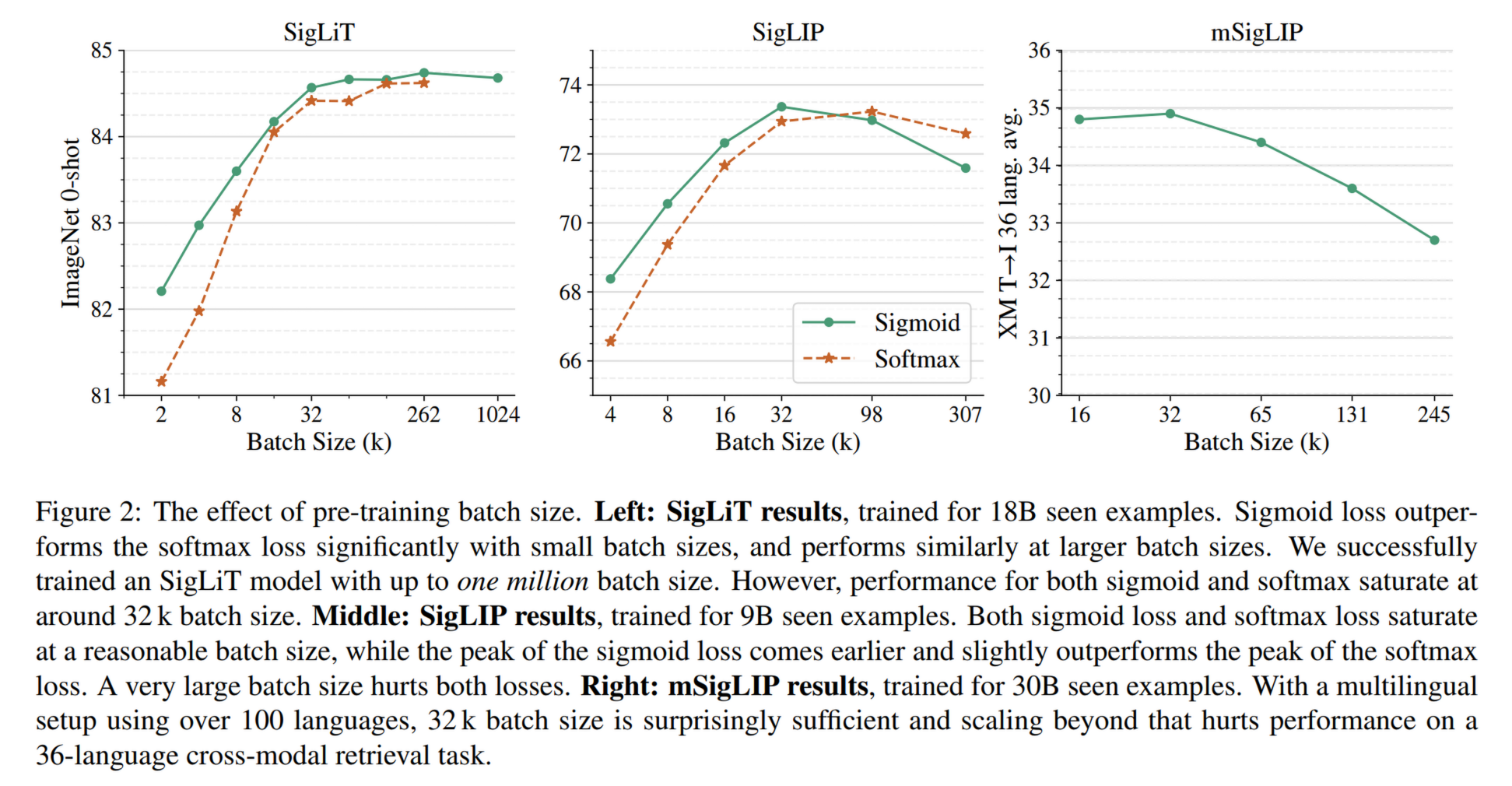
另外,还发现 batch size 并不是越大越好,32k 左右饱和(符合直觉,因为 越大,负样本占比越多,模型学偏的可能性越大)