TL;DR
Meta 发布了一款 32B 参数的开源模型 CWM,它通过学习代码执行过程(而不仅仅是静态文本)掌握了编程的“物理直觉”,在软件工程任务上表现惊人(SWE-bench Verified 65.8%),甚至超越了许多更大规模的模型。
1. 研究背景与痛点
目前的大型语言模型(LLM)在软件开发中应用广泛,但仍面临重大挑战:
- 静态视角的局限性:传统的预训练像处理普通文本一样处理代码(预测下一个 token),模型只知道代码“长什么样”,却不知道代码执行时“发生了什么”。
- 缺乏环境感知:程序员在写代码时会模拟代码如何改变变量状态、如何影响系统。现有的 LLM 缺乏这种**“代码世界模型”(Code World Model)**的能力,即理解代码执行后的动态变化和环境反馈。
- 基准测试的短板:现有模型在生成高质量、可运行、能修复复杂 Bug 的代码方面仍有不足。
Meta 团队旨在通过引入世界模型(World Models) 的概念来提升代码生成的质量。具体来说,就是教模型不仅学习代码的语法,还要学习代码的执行语义(Execution Semantics)和环境交互动态。
2. 核心方法论:如何构建“代码世界模型”?
CWM 的训练流程非常独特,分为三个主要阶段,其中中继训练(Mid-training) 和强化学习(RL) 是核心创新点。
2.0 环境搭建
为了构建大规模仓库來获取大规模运行 trace,作者使用 Docker container,并结合使用 LLM 和 CI 的方式來构建可执行的环境。
- LLM:称为 RepoAgent,输入从仓库中提取的文档,RepoAgent 进行环境构建,直到通过绝大部分单元测试
- 由于文档可能不完整,故只使用 LLM 來搭建环境是不够的
- CI: 开发了名为 Activ 的流水线,将 GitHub Actions CI 用于构建可执行仓库镜像
2.1 数据构建:两大核心支柱
为了让模型学会“代码是如何运行的”,团队构建了两个大规模的新颖数据集:
A. Python 执行轨迹(Python Execution Traces)
- 概念: 这不仅仅是代码文本,而是记录了代码执行每一行后,内存中局部变量的变化
- 规模:
- 函数级追踪:1.2 亿个函数,通过 Fuzzing(模糊测试)和 Llama3 生成输入输出对,记录每一步的堆栈帧。
- 竞赛题追踪:26.2 万个竞赛题解决方案的执行轨迹。
- 仓库级追踪:在真实 GitHub 仓库的单元测试中追踪了 7 万个 commit。
- 格式:CWM 格式。被训练去预测
<代码行>-><变量状态变化>-><下一行代码>。这种训练让模型学会了像“神经调试器”(Neural Debugger)一样思考。
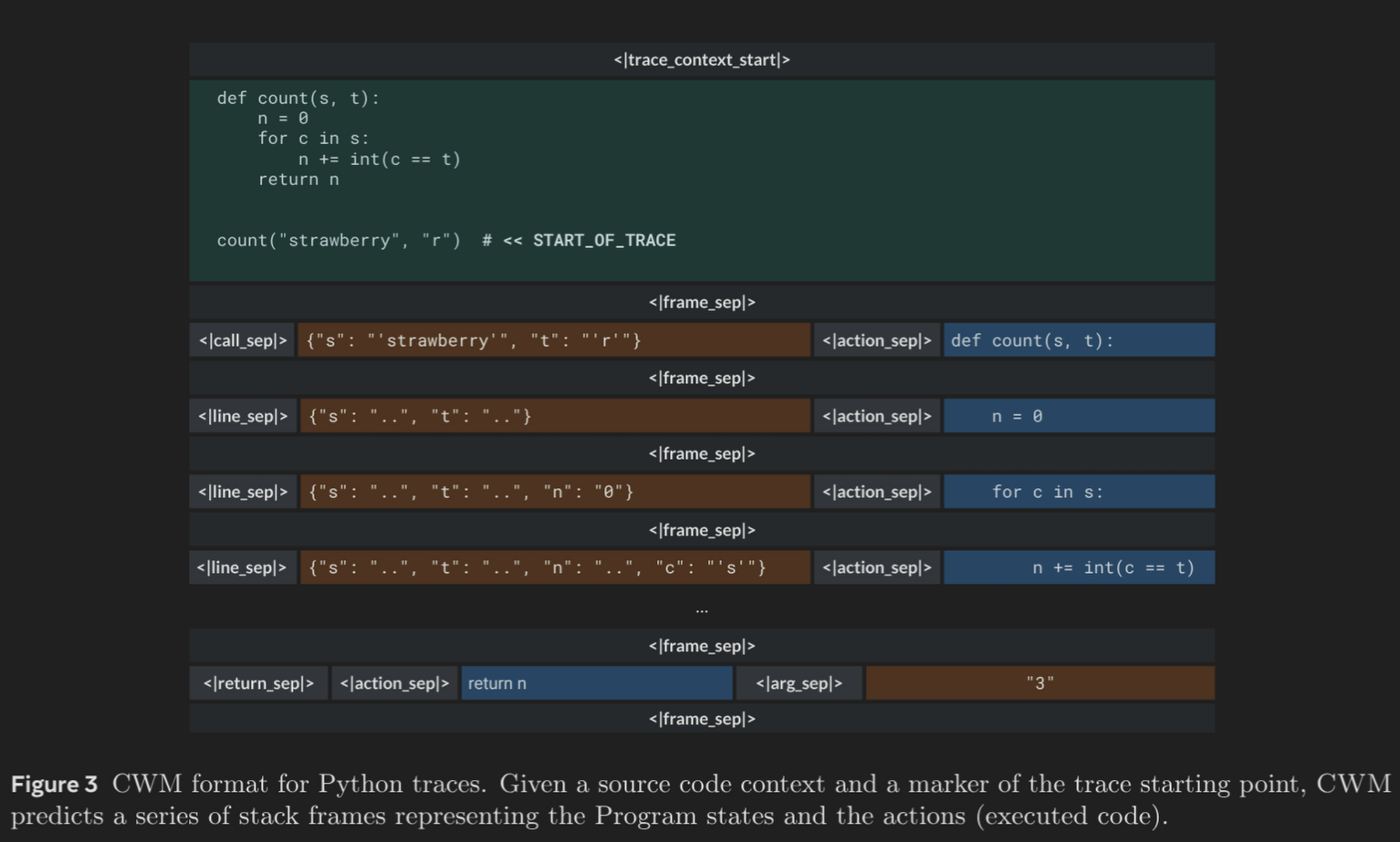
B. ForagerAgent:智能体交互轨迹
- 概念: 让一个 LLM Agent(智能体)在 Docker 容器中模拟软件工程师的行为。
- 任务类型:
- Mutate-fix(变异修复):人为地在好代码里注入 Bug(如删除代码、交换变量),让 Agent 去修复。
- Issue-fix(问题修复):解决真实的 GitHub Issue。
- 数据量:生成了300 万条交互轨迹。
- 意义:让模型在预训练阶段就“见识”过大量的 Linux 命令、文件编辑、测试报错和修复过程,建立对环境反馈的预测能力。
C. 自然语言轨迹
2.2 训练架构与流程
模型基于 Dense Decoder-only Transformer 架构,32B 参数。
- 通用预训练 (General Pre-training):
- 数据量:8T tokens。
- 内容:通用英语文本、代码、数学、STEM 知识。
- 上下文:8k tokens。
- 代码世界模型中继训练 (Code World Model Mid-training):【关键步骤】
- 数据量:额外 5T tokens。
- 核心变化:引入上述的“执行轨迹”和“ForagerAgent”数据。
- 上下文:扩展至 131k tokens。
- 目的:将世界模型的动态知识注入模型权重。
- 后训练 (Post-training):
- SFT (监督微调):100B tokens。混合了指令微调和推理数据(引入
<think>标签进行思维链训练)。 - Joint RL (联合强化学习):172B tokens。这是目前开源模型中非常大规模的 RL 训练。
- SFT (监督微调):100B tokens。混合了指令微调和推理数据(引入
3. 强化学习(RL)详解:CWM 的“实战演练”
CWM 没有使用传统的 RLHF(基于人类反馈),而是使用了完全基于**验证(Verification)**的 RL。
3.1 算法:改进版 GRPO
团队使用了一种改进的 GRPO (Group Relative Policy Optimization) 算法:
- 异步训练:Worker 节点不断生成数据,Trainer 节点异步更新,吞吐量极高。
- 多轮交互:不仅优化单次问答,还优化 Agent 与环境(Docker)的多轮交互。
- 去偏置:移除了长度归一化(避免模型为了降低 Loss 故意写长代码),并不使用 KL 散度约束(依靠 Clip 机制防止崩溃)。
3.2 训练任务与环境
RL 阶段混合了三类任务,迫使模型在不同维度进化:
- Agentic SWE (软件工程):
- 环境:Docker 容器,提供
bash、edit、create、submit工具。 - 奖励:通过单元测试得 1 分,否则得 -1 分(部分情况使用补丁相似度作为奖励)。
- Self-bootstrapping(自举):由于缺乏高质量的推理 Agent 数据,团队先用弱模型生成大量轨迹,过滤出成功的,再微调模型,循环迭代提升数据质量。
- 环境:Docker 容器,提供
- Coding (竞技编程):
- Python 和 C++,要求通过所有测试用例。
- Mathematics (数学):
- 要求推理过程正确且最终答案(LaTeX 格式)与标准答案一致。
4. 关键发现与实验结果
4.1 性能表现
CWM (32B) 展现了超越其参数规模的性能,甚至能够挑战更大或闭源的模型:
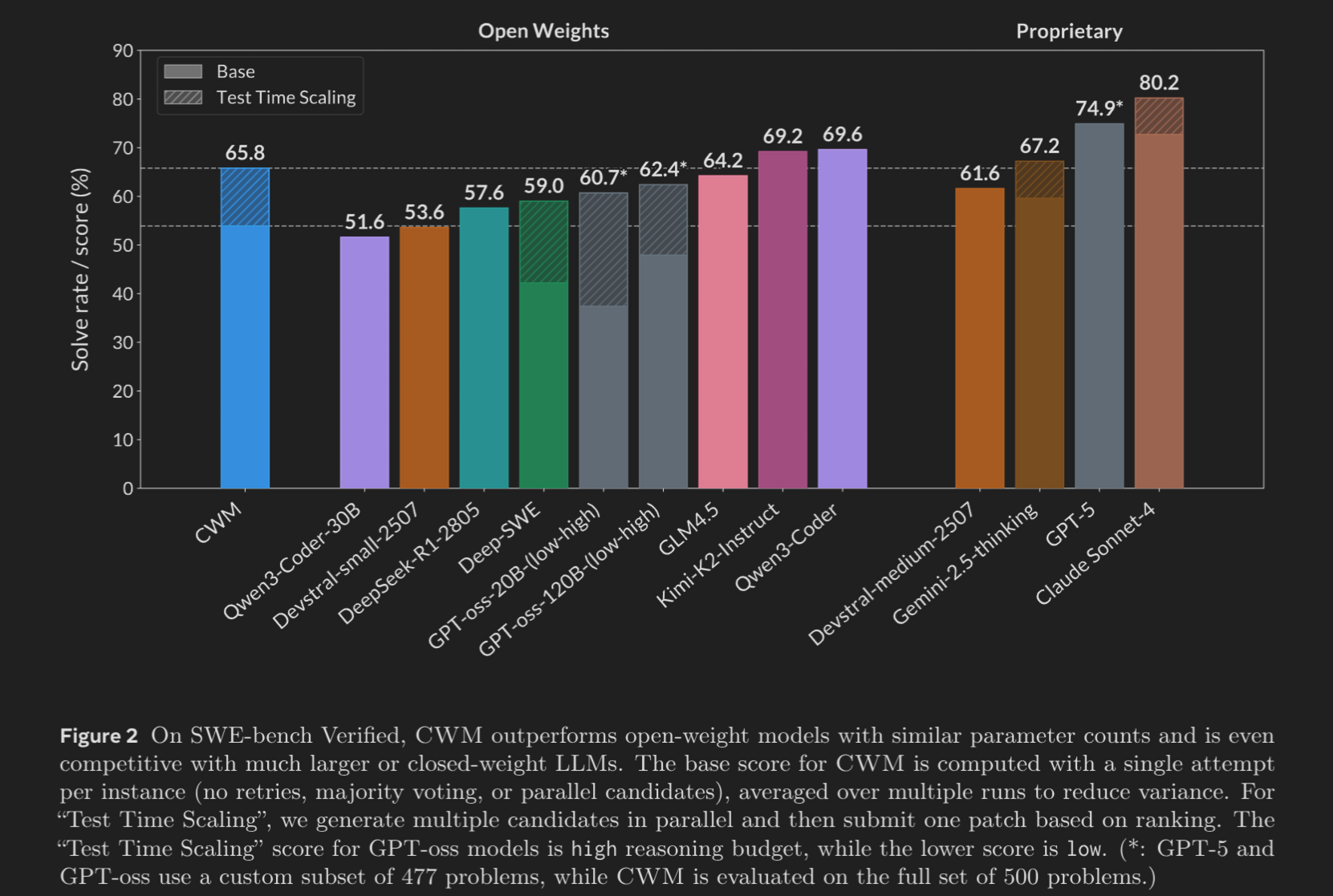
- SWE-bench Verified (软件工程标杆):
- 65.8% (Pass@1, with Test-Time Scaling):击败了同等规模的开源模型。
- 53.9% (Base score):单次尝试表现依然强劲。
- 竞争力:性能接近 GPT-4o 和 Claude 3.5 Sonnet 等闭源前沿模型,且优于 GPT-oss-120B。
- LiveCodeBench:68.6%,表现优异。
- CruxEval:94.3%
- 数学能力:Math-500 上达到 96.6%,AIME 2024 上达到 76.0%。
4.2 消融实验(Ablation Studies)
世界模型数据的作用:实验证明,在中继训练中加入“执行轨迹”和“ForagerAgent”数据,显著提升了下游任务(如 CruxEval 和 SWE-bench)的表现。只加代码不加轨迹,效果会打折。
4.3 新颖能力展示
得益于独特的训练数据,CWM 涌现出了一些通用模型不具备的能力:
- 执行轨迹预测 (Execution Trace Prediction):
- CWM 可以充当“神经解释器”。给定一段代码,它可以一步步预测变量的值如何变化,准确率极高(CruxEval 上 Valid Trace Format 达到 99.6%)。
- 应用:这意味着模型可以进行“脑内调试”,甚至预测死循环(程序终止预测)。
- 算法复杂度预测:
- 在 BigO-Bench 上,CWM 在预测代码的时间复杂度和空间复杂度方面表现出色。
5. 通俗解释新颖概念
为了帮助理解,这里对文中的关键概念进行类比:
- 世界模型 (World Model):
- 通俗解释:想象你在学开车。如果你只是背诵交规(静态代码训练),你可能考过笔试,但上路会慌。如果你在模拟器里开了几千小时,知道踩油门车会冲、撞墙车会坏(世界模型),那你实际上路时就会通过“预测后果”来驾驶。CWM 就是那个在“代码模拟器”里训练过的司机。
- 执行轨迹 (Execution Trace):
- 通俗解释:相当于代码的“慢动作回放”。普通训练只给模型看“代码 A -> 结果 B”。CWM 的训练是看“代码 A -> 第一行运行,变量 x 变了 -> 第二行运行,变量 y 变了… -> 结果 B”。这让模型拥有了透视代码内部逻辑的 X 光眼。
- 中继训练 (Mid-training):
- 通俗解释:这是介于“读完小学(预训练)”和“岗前培训(SFT)”之间的“大学专业课”。在这个阶段,模型专门大量阅读高难度的专业材料(长上下文、执行轨迹),从而发生质变。
- Test-Time Scaling (测试时扩展):
- 通俗解释:俗称“三个臭皮匠顶个诸葛亮”。在解决难题时,让模型生成多个方案(比如 16 个),或者让模型多思考一会儿,然后选最好的那个。CWM 证明了它极其擅长这种“多想一下”的策略。
6. 结论与局限性
结论
CWM 的发布证明了:
- 不仅仅是预测文本:教模型理解代码的执行(Execution)和环境(Environment)是提升代码能力的关键。
- 开源的力量:32B 的参数量配合高质量的“世界模型数据”和 RL 训练,可以达到甚至超越闭源大模型的代码能力。
- 未来方向:通过预测执行轨迹来辅助推理(Reasoning-via-tracing)是一个极具潜力的方向,可能演化出能自我验证和自我修复的超级程序员 AI。
局限性
- 非通用聊天机器人:CWM 专精于代码和推理,可能在闲聊、事实性知识或多语言(非英语)任务上表现不如通用模型。
- 安全性:作为科研模型,虽然经过初步过滤,但未经过像商业模型那样严格的对抗性安全对齐。
总结:CWM 是一项具有里程碑意义的工作,它将大模型从“静态代码生成器”推进到了“动态代码推理者”的层面,为未来的 AI 编程工具树立了新的范式。