[2603.17378] Efficient Exploration at Scale Google DeepMind
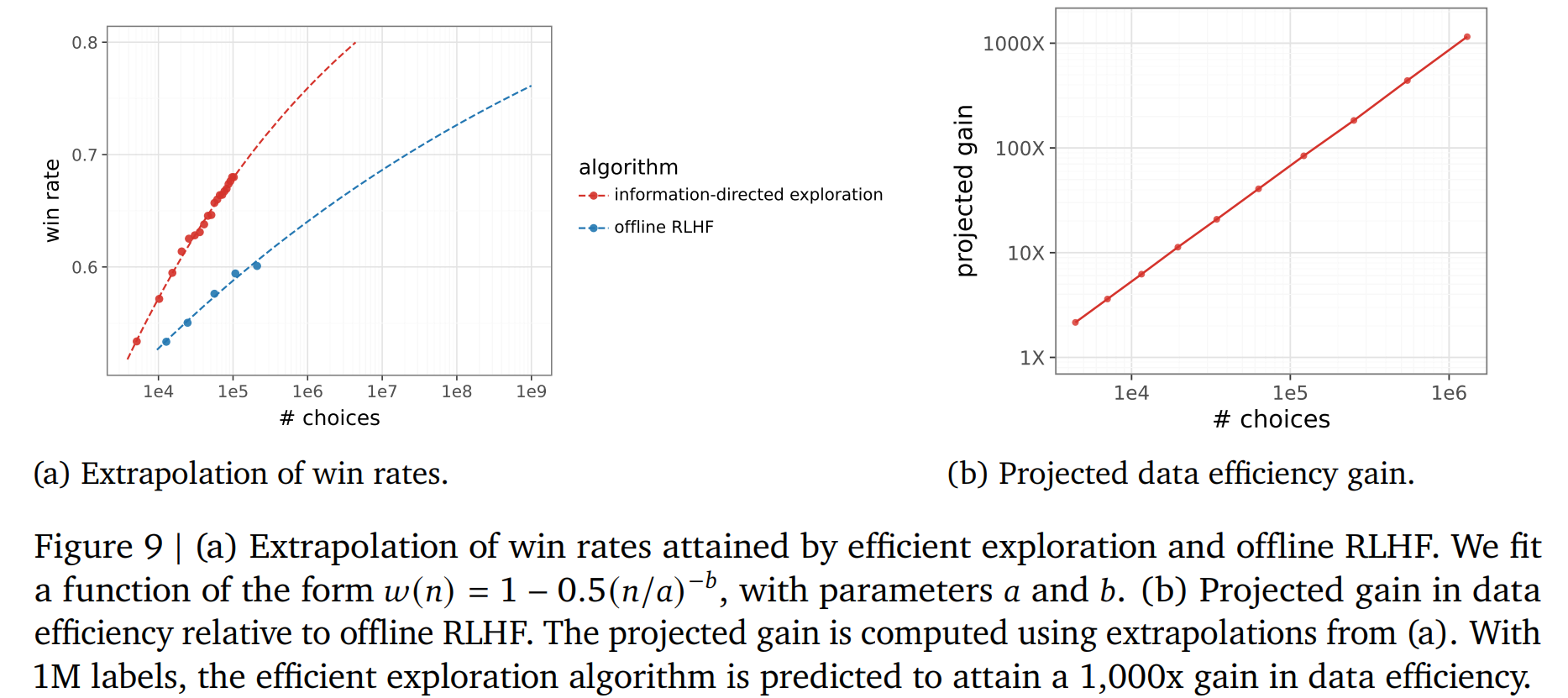
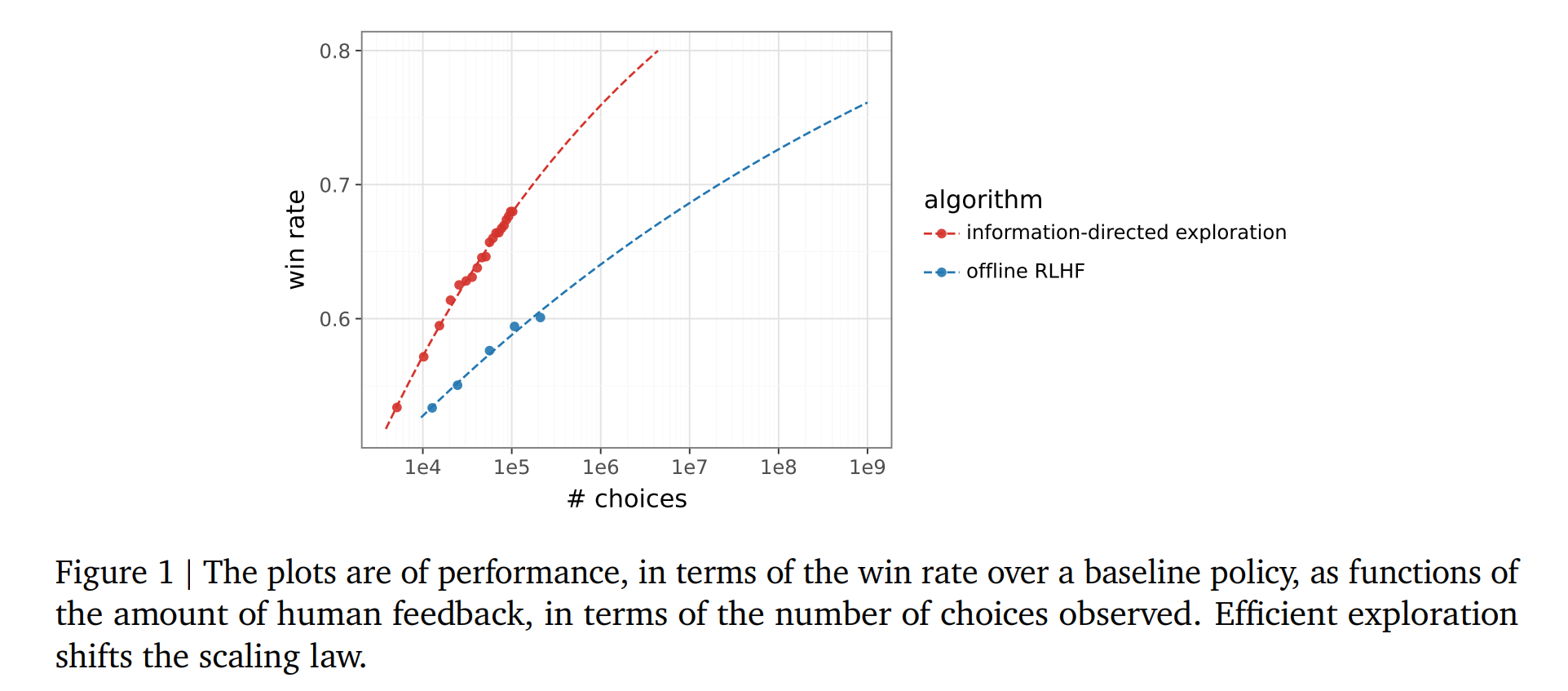
- 提出了 reinforce 算法一个的变体,使用 20k 样本就达到了 offline 200k 样本的训练质量
- Base model: Gemma 9B(经过 pre-train 和 SFT)
- Human Feedback:使用 Gemini 1.5 Pro 模拟,根据 Bradley-Terry 模型进行打分选择
- 数据集:202k 的内部数据
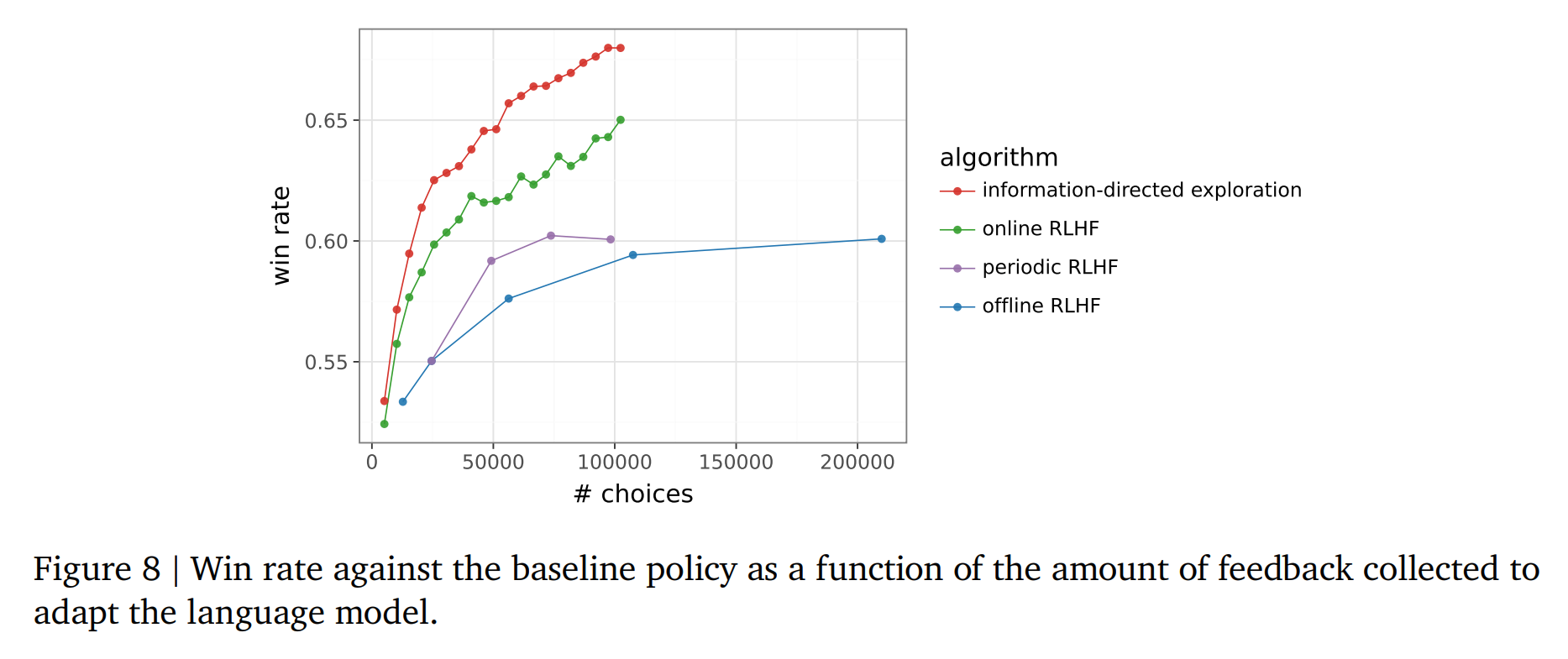
对比了四种算法 :
- Offline RLHF:固定数据集训练 RM,再优化 LM
- Periodic RLHF:分阶段收集数据并重新训练模型
- Online RLHF:每获得一轮数据即增量更新模型
- Information-Directed Exploration:在 Online 基础上增加不确定性引导的响应选择
对 reward model:
基于 Bradley-Terry 模型,给定提示词 和响应对 ,模型预测 优于 的概率为:
通过最大化对数似然进行参数 的更新,梯度为:
对 policy model:
为了防止模型在更新中偏离太远,算法首先维护了一个参数的指数移动平均 (Exponential Moving Average) 作为“锚点 (anchor)” :
policy gradient 为:
其中
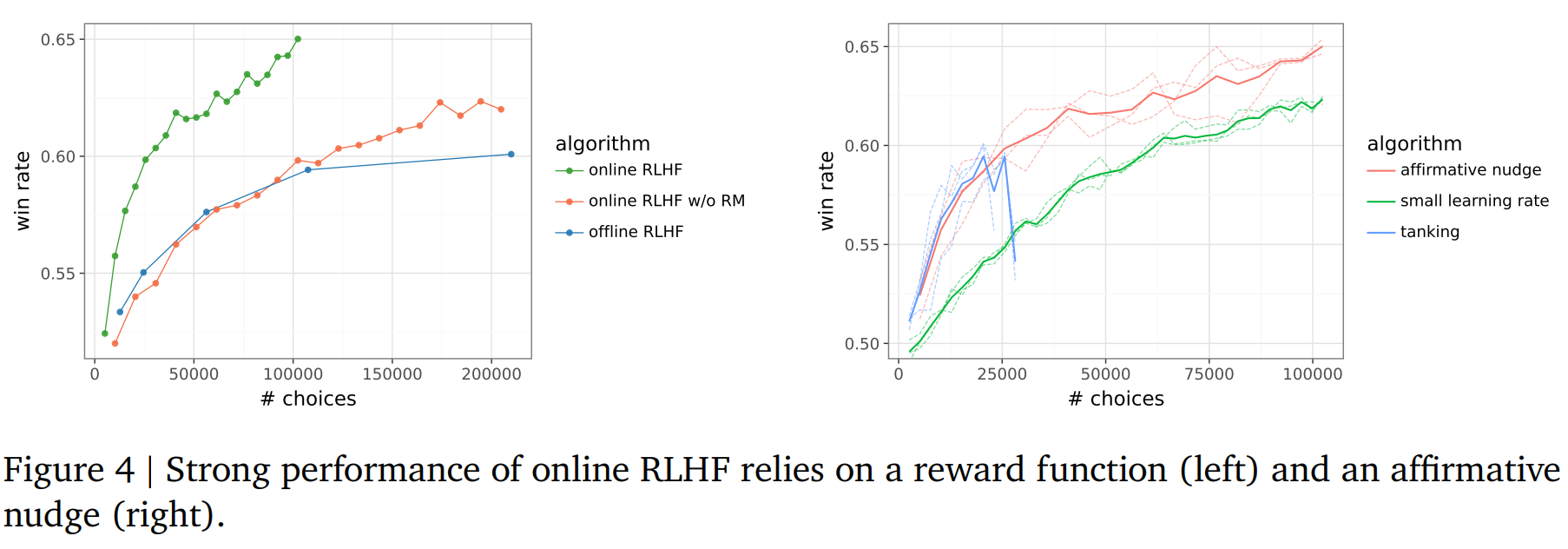
传统的强化学习更新信号为 。为了防止性能崩塌,作者引入了 (Affirmative Nudge):
其中 的加入确保了即使在奖励不确定时,模型也能获得微小的正面鼓励,从而维持训练稳定性
文中还引入了认知神经网络 (Epistemic Neural Network, ENN),该网络引入了一个额外的输入 ,称为认知索引 (Epistemic Index) 。 是一个从 0 到 100 的整数,它像一个“开关”,决定了数据在网络头部 (Head) 的流向
ENN 享一个包含约 90 亿参数的 Transformer backbone,但在头部进行了特殊设计(增加的参数量远不到总量的 5%) :
- 点估计网络 ():这是一个标准的 MLP 头部(命名为
mlp 0,含两层隐藏层,宽度为 1024) 。当 时,模型就走这条标准推断路径,输出基础的奖励预测 - 集成粒子网络 ():为了构建不确定性,模型并行训练了一个包含 100 个粒子的集成 (Ensemble) 。每个粒子由两部分组成,且在初始化时都被赋予了随机权重 :
- 先验网络 (Prior Networks):100 个较小的 MLP(宽度 256)
- 差分网络 (Differential Networks):100 个较大的 MLP(宽度 1024)
- 计算方式:当 时,第 个集成的最终奖励输出,是将对应的先验网络和差分网络的输出值相加得到的 。
核心作用是找出那些“模型内部最拿不准”的回复对,把它们挑出来让人类去评判。具体流程:
- 采样候选:给定一个批次中的某个提示 ,策略模型首先会生成 16 个不同的候选回复
- 计算偏好概率:对于这 16 个回复中任意组成的一对 ,ENN 会代入 ,让 100 个集成粒子分别计算一次“ 优于 的概率”: 。
- 计算方差 (衡量不确定性):计算这 100 个概率值的方差 (Variance) 。
- 方差小:说明 100 个粒子给出的预测高度一致,模型对这对回复的优劣已经很确定,让人类再选一次带来的信息量很低
- 方差大:说明 100 个粒子产生了严重分歧,模型极度不确定
- 信息最大化查询 (Infomax):算法最终会挑选出方差最大的那对回复 ,将其发送给人类(或模拟器)进行偏好选择 。这就保证了收集到的每一条反馈都具有最高的信息价值
更新策略:
- 更新点估计网络: 的路径使用与常规在线 RLHF 完全相同的损失函数和梯度更新方式
- 更新差分网络:100 个差分网络会根据各自的预测误差单独进行更新,但在更新它们时,底层的 Transformer 骨干参数会被冻结
- 冻结先验网络:100 个先验网络在整个训练过程中永远不会被更新 。它们作为随机初始化的锚点(Randomized Prior Functions),强迫各个粒子保持差异性,从而防止整个集成模型在训练中坍缩成完全相同的预测