[2603.16856] Online Experiential Learning for Language Models
主要贡献
- 提出在线经验学习(OEL)框架:传统模型通常在闭源的离线数据或模拟环境中训练,部署后就变成了静态产物,无法利用真实世界中积累的丰富经验。OEL 框架打破了这一瓶颈,使模型能够利用自身的部署经验持续自我提升
- 实现完全“无奖励”的学习机制:该方法不需要服务端访问用户环境,不需要人工标注,也不需要构建可验证的奖励函数或独立的奖励模型。它完全依靠从环境中获得的纯文本反馈来提取训练信号
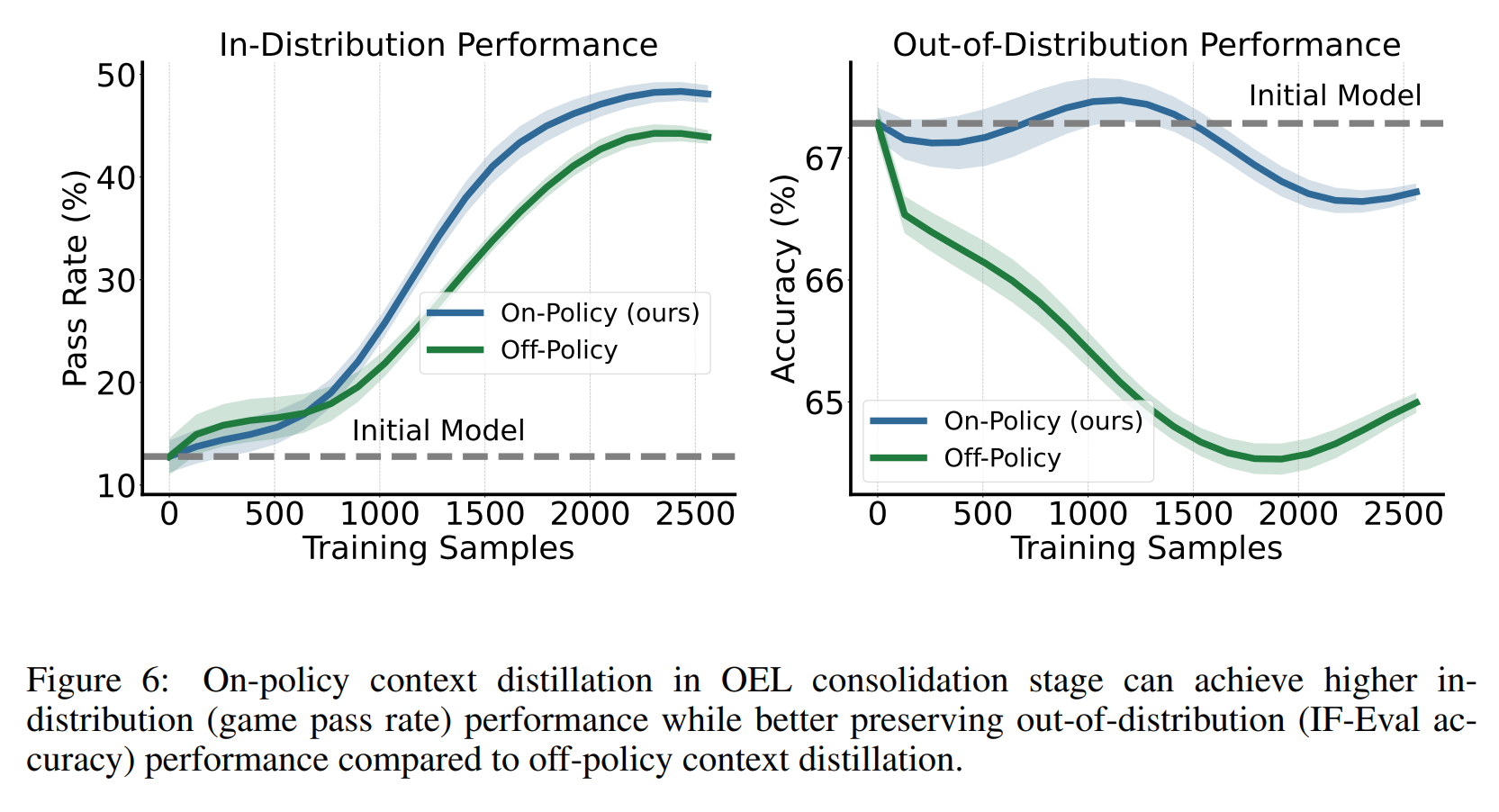
- 解决灾难性遗忘问题:通过结合“同策略”(on-policy)的上下文蒸馏技术,模型在学习新领域经验的同时,有效保持了原有的 OOD 通用能力
算法流程
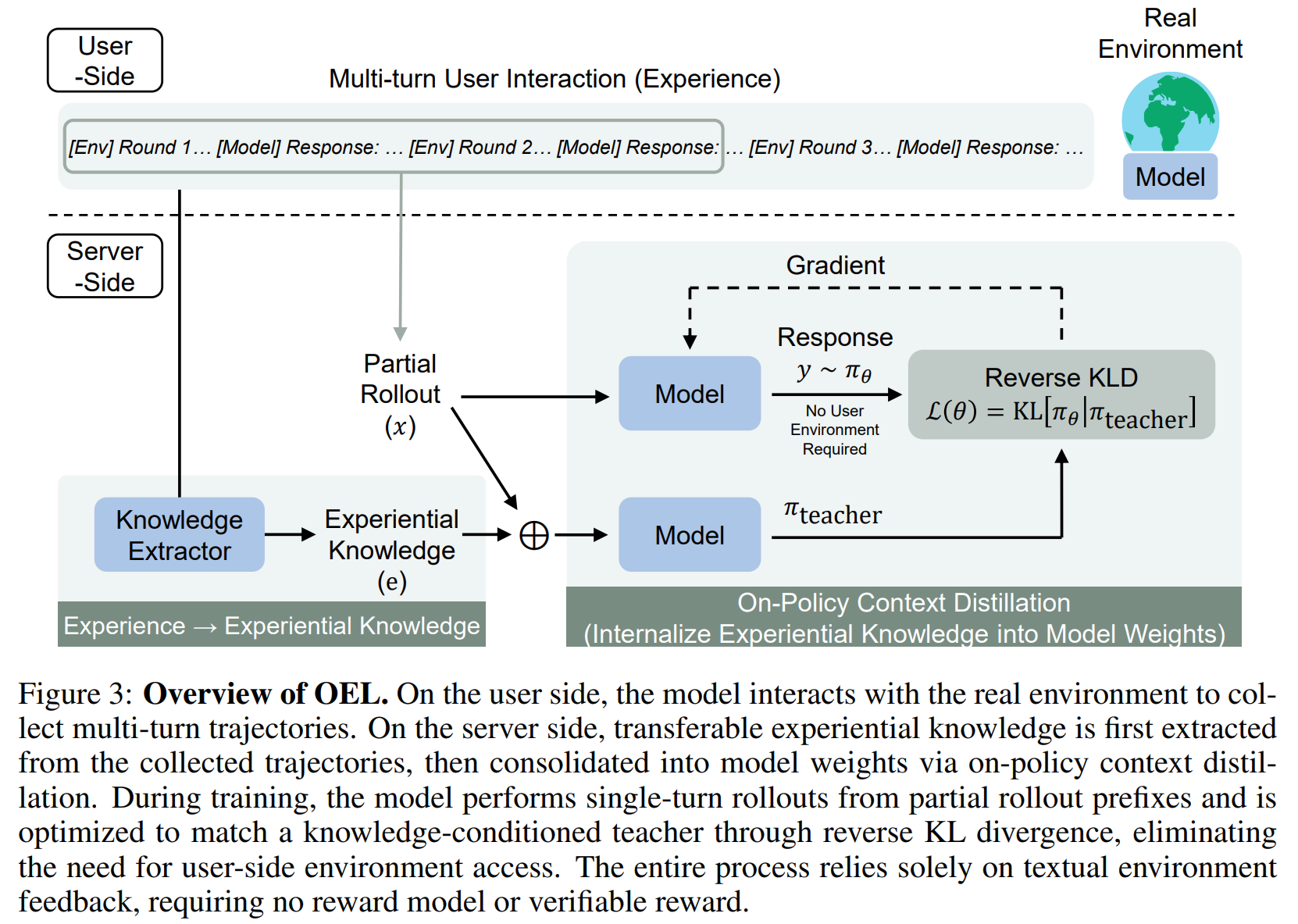
- 阶段一:从用户轨迹中提取经验知识(Extraction)
- 用户端的 与用户交互,获得一批轨迹
- 服务端的 对每个 ,参考以前的经验,来生成新的经验集合
- 阶段二:将经验知识巩固到模型参数中(Consolidation)
- 再在用户端生成一批轨迹 ,并采样前缀得到
- 对每条 ,随机抽取一个 拼接到 前面,给冻结的教师模型 (就是冻结的 ; 直接给学生模型 (就是 )
- 用反向的 KL 散度作为 loss(参考 GRPO 为什么加上 KL 散度,用的 KL 散度是正向 KL 散度还是反向?)
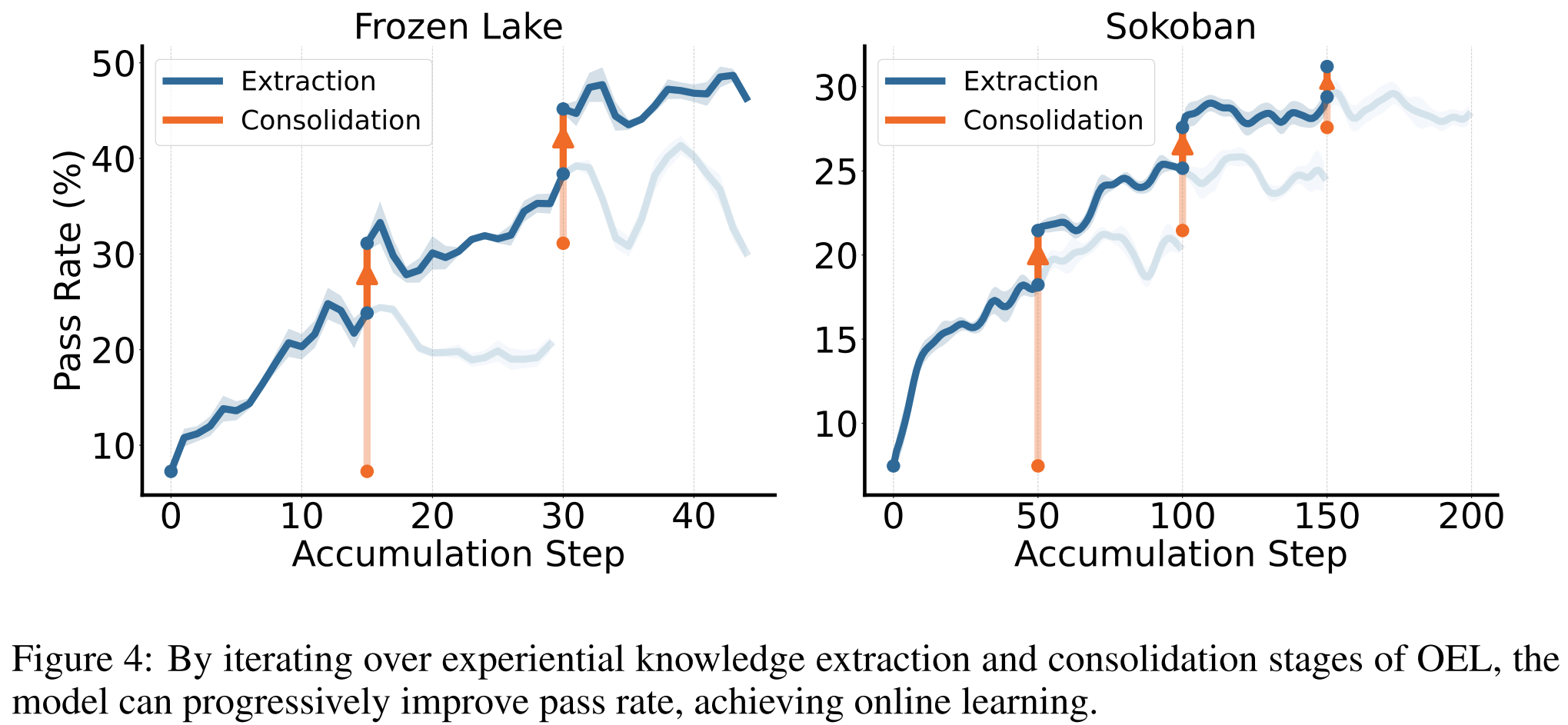
- 在线学习循环(Online Learning Loop)
- 将更新后的 代替原有用户和服务端的模型
其中 loss 为:

实验结果