[2602.01058] Good SFT Optimizes for SFT, Better SFT Prepares for Reinforcement Learning
这篇文章《Good SFT Optimizes for SFT, Better SFT Prepares for Reinforcement Learning》针对当前大语言模型(特别是推理模型)后训练(Post-training)的标准范式——“离线监督微调(SFT)+ 在线强化学习(RL)”,提出了一个非常深刻的洞察:最好的离线 SFT 性能,并不意味着能为后续的 RL 提供最好的初始化。
为了解决离线 SFT 和在线 RL 之间的分布不匹配问题,作者提出了一种名为 PEAR (Policy Evaluation–inspired Algorithm for Offline Learning Loss Reweighting) 的算法。
以下是对该文章提出的算法、创新点、重要实验结果及深度分析的详细讲解:
一、核心动机与创新点
1. 核心动机:Offline Online
当前很多研究致力于改进 SFT 的损失函数(如根据 token 概率进行重加权、过滤低置信度 token 等),但这些方法大多在孤立地优化离线性能(例如直接提高 SFT 后的准确率)。
作者通过实验发现了一个反直觉的现象:离线阶段表现更强的检查点(Checkpoint),在经过完全相同的在线 RL 训练后,其最终性能甚至可能不如离线表现较弱的模型。这说明仅仅追求离线准确率,对于以“强 RL 最终表现”为目标的流水线来说,可能是适得其反的。
根本原因在于“分布不匹配(Distribution Mismatch)”:
- 离线 SFT:模型从行为策略(Behavior Policy, 即生成数据的策略 ) 产生的数据分布中学习。SFT 是统一地对待所有 token 的。
- 在线 RL:目标策略(Target Policy, 即当前正在训练的模型 ) 通过自身生成的轨迹进行学习。
在自回归长逻辑推理中,SFT 可能会强迫模型学习一些在 下合理,但在当前 看来是“死胡同”的轨迹。如果在线 RL 永远不会采样到这些前缀,那么 SFT 在这些轨迹上耗费的梯度更新就是无效甚至有害的。
2. 主要创新点
- 视角的转变:打破了“好 SFT = 高准确率”的传统认知,提出 SFT 的真正目标应该是为在线 RL 提供有利于持续改进的初始化。
- 引入离线策略评估(OPE)思想:借鉴强化学习中的 OPE 技术,利用重要性采样(Importance Sampling)来量化并纠正 SFT(行为策略)与 RL(目标策略)之间的分布偏差。
- 着眼于“未来”的重加权(Suffix-based Weighting):证明了仅根据当前 token 概率进行重加权(Single-step)是短视的,必须考虑该 token 之后的后缀(Continuation/Suffix) 在当前策略下的合理性。
- 即插即用的通用性:PEAR 可以在不改变基础损失函数(无论是标准 NLL 还是 KL 散度知识蒸馏 KD)的情况下,仅通过修改 token 的权重(Weighting)来实现,几乎不增加额外的训练开销。
二、PEAR 算法详解
PEAR 的核心思想是:如果一条数据轨迹在当前目标模型 看来是极不可能生成的,那就降低这条轨迹(或 token)在 SFT 中的损失权重;反之则提高。
具体来说,算法定义了目标策略与行为策略在位置 的概率比值:
这里的 是生成 SFT 数据轨迹所使用的模型(通常是能力更强的 teacher 模型),而 则是当前正在训练的模型
PEAR 保持基础的 per-token 损失 不变,只是在外面乘上一个停止梯度更新(stop-gradient)的权重 。文章提出了三种计算权重的变体:
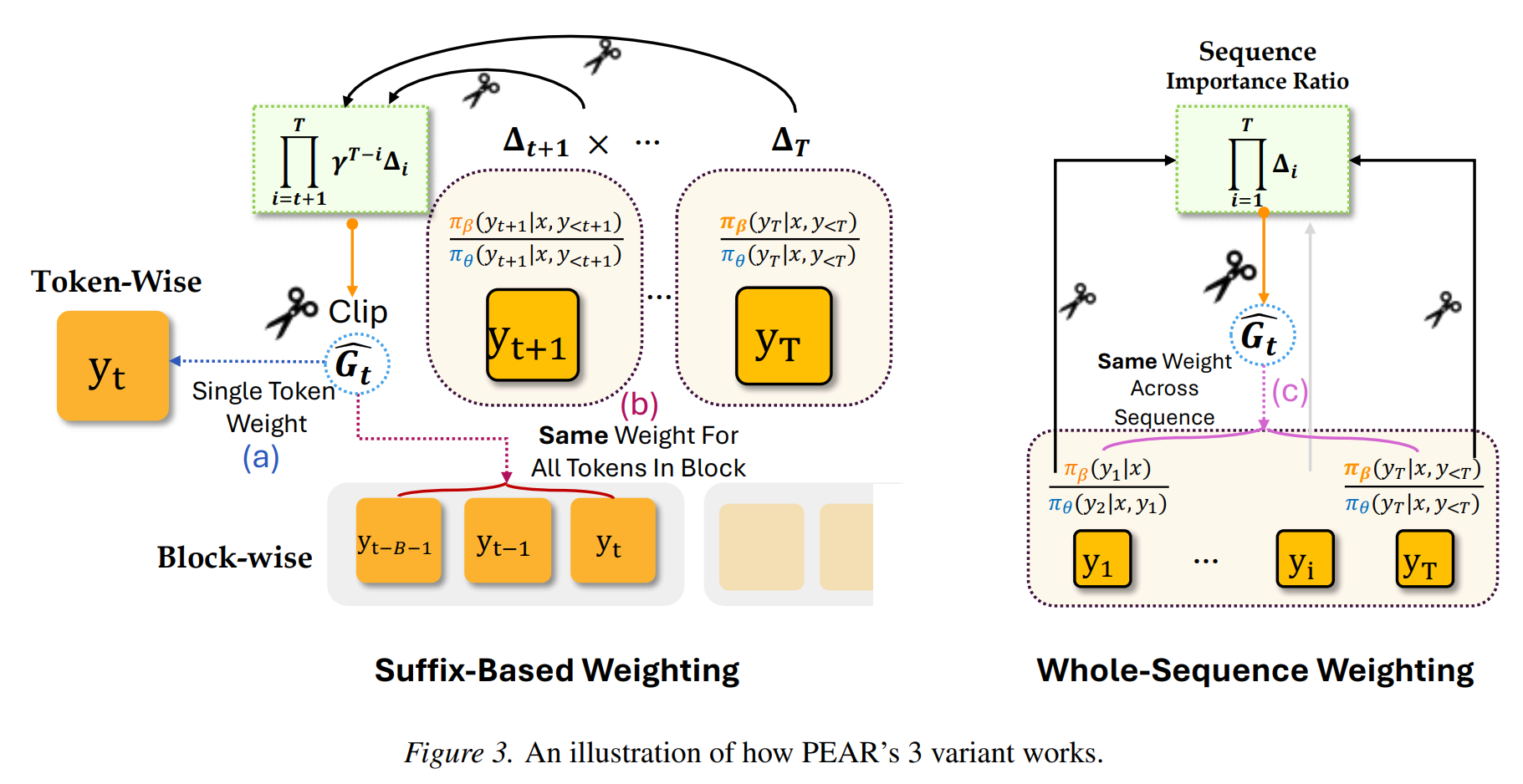
1. 序列级别加权 (Sequence-Level Weighting)
最简单的形式,计算整条序列的重要性比率:。
整条序列中的每一个 token 都共享这同一个权重 。
2. 基于后缀的 Token 级别加权 (Token-level Weighting Based on Continuation) —— 这是默认且表现最好的版本 (PEAR)
序列级加权粒度太粗。对于序列中的某个 token ,PEAR 评估的是:在已经生成 的情况下,后续的真实轨迹(Suffix)在当前模型看来是否仍然合理?
如果后续轨迹在当前模型下概率极低,说明当前模型在 RL 阶段几乎不可能走到那里,那么当前 token 的梯度更新就是无意义的。
因此,权重定义为后缀概率比的乘积(并引入折扣因子 控制长序列方差):
3. 块级别加权 (Block-Level Weighting)
长序列中连乘会导致极大的方差和数值不稳定。为了在粒度和稳定性之间折中,作者将序列划分为大小为 的连续块(Blocks)。在一个块内的所有 token 共享相同的、基于该块之后的后缀计算出的权重。
4. 数值稳定与负样本利用
- 数值稳定:所有的权重计算都在对数空间(log-space)进行,并且对单步比率 和最终权重 进行了截断(Clipping),防止梯度爆炸。
- 负样本 (Negative Examples):如果离线数据集包含验证失败的错误回答,PEAR 可以加入一个排斥项,使用序列级权重执行梯度上升,将模型推离那些与当前策略兼容的错误轨迹。
三、实验结果
作者在纯净可验证的逻辑游戏(SynLogic/Enigmata)和数学推理(MATH-500, AIME 等)上进行了严格的控制实验。使用的模型涵盖 Qwen2.5/3 (0.6B 到 8B) 和 DeepSeek-Distilled 模型
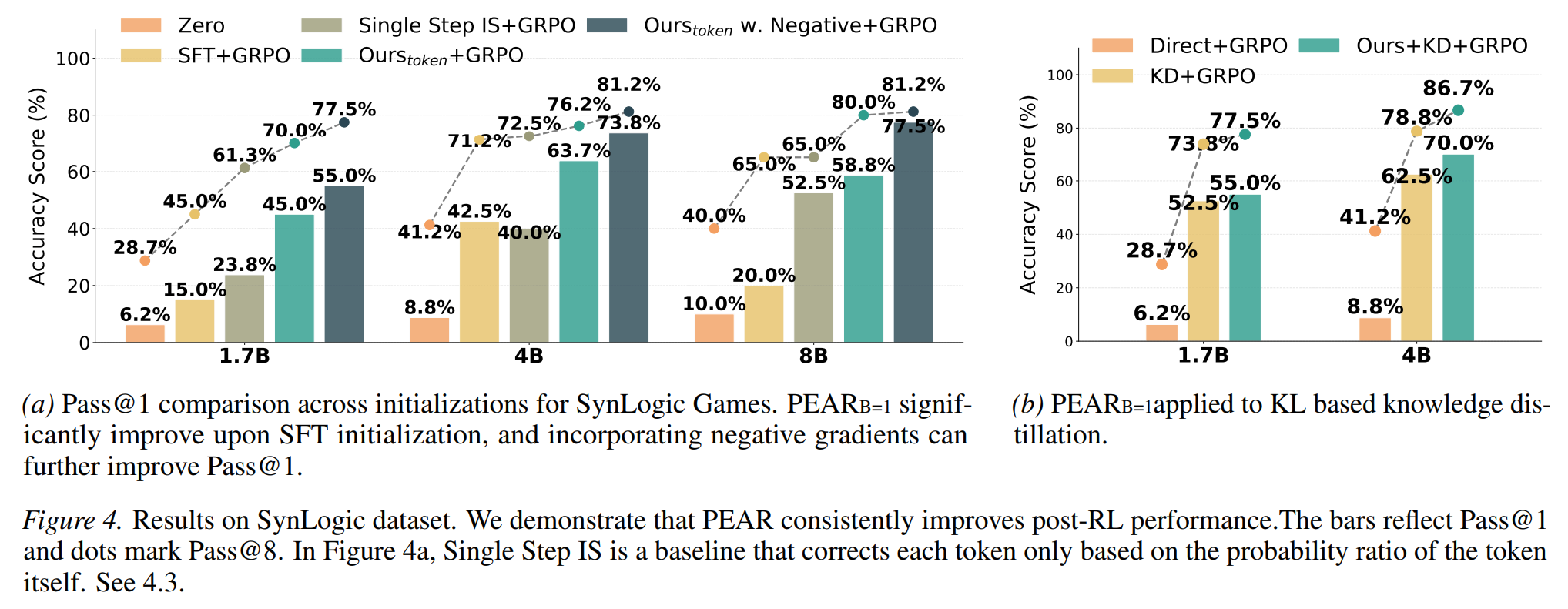
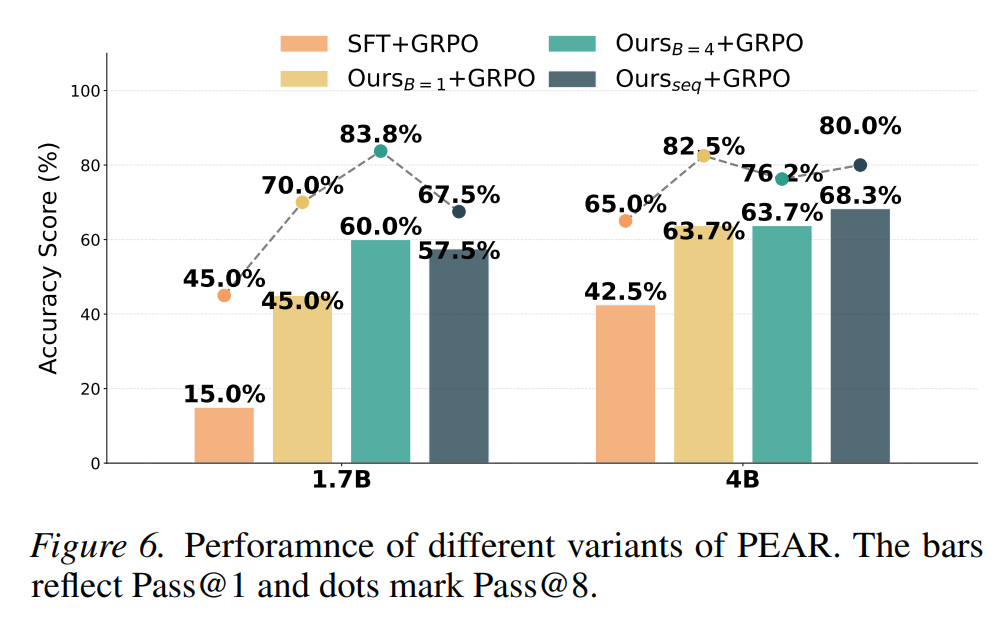
1. RL 后的最终性能全面超越
在保持 RL 阶段算法(GRPO)、超参数和计算预算完全一致的前提下,使用 PEAR 初始化的模型,其最终表现显著优于标准的 SFT 和其他花哨的 SFT 变体
- 在 Qwen3-1.7B 模型上,相比标准 SFT,PEAR 在逻辑游戏上提升了 40% 的绝对准确率;在 AIME-2025 上实现了 14% 的 Pass@8 提升。
- 在各种不同规模的模型(0.6B 到 8B)上,PEAR 均稳定带来增益。
2. 打破 “离线好 = 在线好” 的错觉 (Offline Online)
实验清晰地展示了“排名反转(Rank Reversals)”:
- TopLogP (SFT 变体)在纯离线阶段获得了最高的 Pass@1 分数。但用它作为起点跑完 RL 后,其最终表现却是最差的,甚至不如原始的 SFT
- 相反,PEAR 在离线阶段的准确率可能不如某些算法(因为它本质上是为了迎合 RL,而不是死记硬背离线数据),但在 RL 阶段后,效果却大幅领先
3. 跨分布转移能力 (Transfer to Different RL distributions)
作者用 PEAR 在 SynLogic 任务上做离线训练,然后在一个略有差异的未见任务(Enigmata 的一个子集)上做在线 RL。结果表明,PEAR 的优势并未过拟合于离线数据域,它依然能为偏移后的 RL 分布提供更强的初始化。
4. 完美兼容知识蒸馏 (KD) 与负样本
- 如果基础的 SFT 损失换成 KL 散度蒸馏(向更强的教师模型学习),PEAR 的加权方案依然有效,并能进一步提升 RL 后的表现。
- 在加入负样本的对比实验中,结合负样本排斥梯度的 PEAR 进一步拉高了 Pass@1。
四、深入分析
为了理解 PEAR 为什么这么好,作者进行了深入的技术分析:
1. PEAR 到底重点关注了哪些位置? (RQ1)
作者通过计算 发现,PEAR 给高权重的 token,往往是那些在分布上被大幅偏转的 token。也就是说,PEAR 在离线训练时,系统性地将模型的行为了引导到了那些能够“成功导向合理后缀”的关键决策点上,而不是在整个句子上平均用力。
2. PEAR 的梯度如何与在线 RL 交互? (RQ2: Gradient Rotation)
这是文章非常精彩的一个分析。作者测量了离线阶段的梯度与在线 GRPO 阶段的梯度之间的平均主视角(Principal Angle)
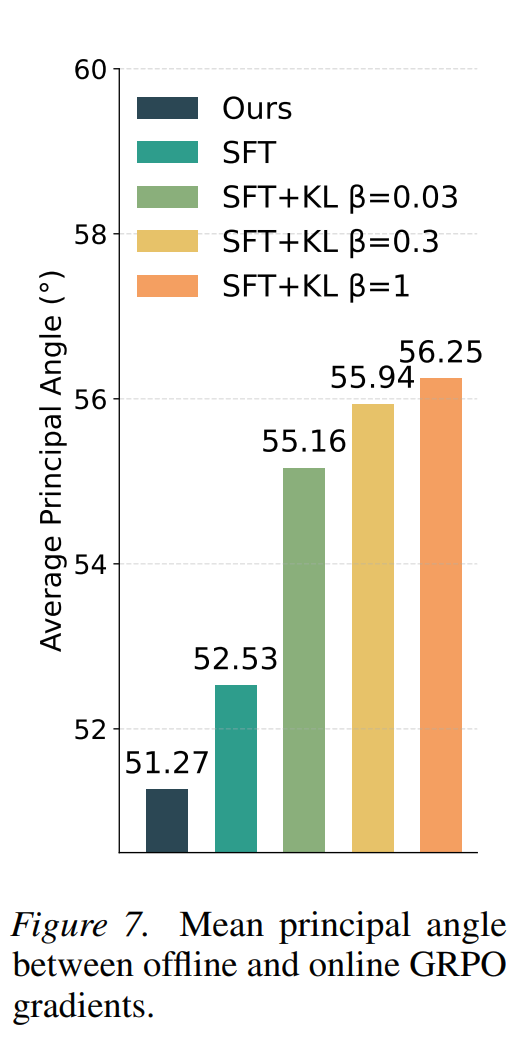
- 结论:PEAR 离线训练的梯度方向,与在线 GRPO 的学习方向夹角更小(更一致)
- 意义:这意味着 PEAR 在离线阶段就已经在做“类似在线 RL 想做的事情”,使得线下线上的更新方向保持一致,减少了 RL 阶段纠正 SFT 错误所带来的内耗
3. 参数漂移(Parameter Drift / NSS)
- SFT 加入强 KL 惩罚(SFT+KL)会使得离线模型与基础模型非常接近(漂移小),但这反而损害了后续的 RL 性能
- 相比之下,PEAR 在离线阶段造成了更大的参数漂移(承担了重活/heavy-lifting),但在进入在线 RL 后,其参数漂移量(NSS 漂移)反而最小。 这说明 PEAR 使得模型以一种使得后续 RL 高效且平滑的方式进行了参数预调
4. 为什么不能只看当前步(Single-step Weighting 失败的原因)
并发工作中有提出仅基于当前步概率比 进行重加权的。但实验表明,这种方法效果微弱。作者指出:这是一种“近视(Myopic)”的目标。一个 action 当前看起来概率很高,但如果它导致了一个死胡同,RL 依然学不到东西。“你需要权衡未来,而不是单个动作”,这也是 PEAR 后缀加权成功的核心原因
五、总结
这篇文章的最大贡献在于重塑了我们对 LLM 后训练 pipeline 的理解:在两阶段(SFT RL)训练中,我们不应该单纯评估 SFT 拟合数据的能力,而应该评估它对目标 RL 策略的兼容度
PEAR 算法通过巧妙借鉴强化学习中的 OPE 重要性采样,将“过去(行为策略)”与“未来(目标策略)”桥接起来,通过抑制死胡同前缀、放大可达后缀,为 RL 提供了一个方向一致、阻力最小的绝佳起跑线。其实验极其详实,分析直击本质,是一篇非常扎实且具有高度启发性的工作