TL;DR
大型推理模型(Reasoning Models,如 DeepSeek-R1, OpenAI o1)虽然推理能力强,但它们通常通过生成极长的顺序思维链(Chain-of-Thought, CoT)来解决问题,导致推理时间(延迟)非常长。SPRINT 提出了一种新的框架,让模型学会动态规划并并行执行推理步骤,在保持(甚至提高)准确率的同时,显著减少了顺序生成的 Token 数量(即降低了延迟)。
1. 核心理念与算法框架
SPRINT 的名字灵感来源于敏捷开发中的 “Sprint”(冲刺):即包含一个规划阶段,随后是并行的增量执行。
1.1 推理时的机制(Inference-Time)
SPRINT 将推理过程重构为一个**滚动规划与执行(Rolling Horizon Planning and Execution)**的循环。系统中包含两个角色(通常由同一个经过微调的模型扮演):
- 规划者(Planner)
- 执行者(Executor,多个)
工作流程(如图 1 所示):
- 规划阶段 (Planning): 规划者查看当前上下文(问题 + 之前的执行结果),生成一个
<Plan>。在这个 Plan 中,模型会“大声思考”并识别出哪些子任务是独立的。一旦识别出任务,它会生成<prompt>标签。 - 并行执行阶段 (Parallel Execution): 系统提取规划者生成的多个
<prompt>,并将它们并行分发给多个执行者实例。每个执行者根据 Prompt 独立生成思维链(CoT)来解决该子任务。 - 同步阶段 (Syncing): 所有执行者的输出被收集并标记为
<execution>,按顺序拼接到上下文末尾。 - 循环: 规划者接收新的完整上下文,决定是继续下一轮规划,还是生成
<Final_Answer>结束推理。
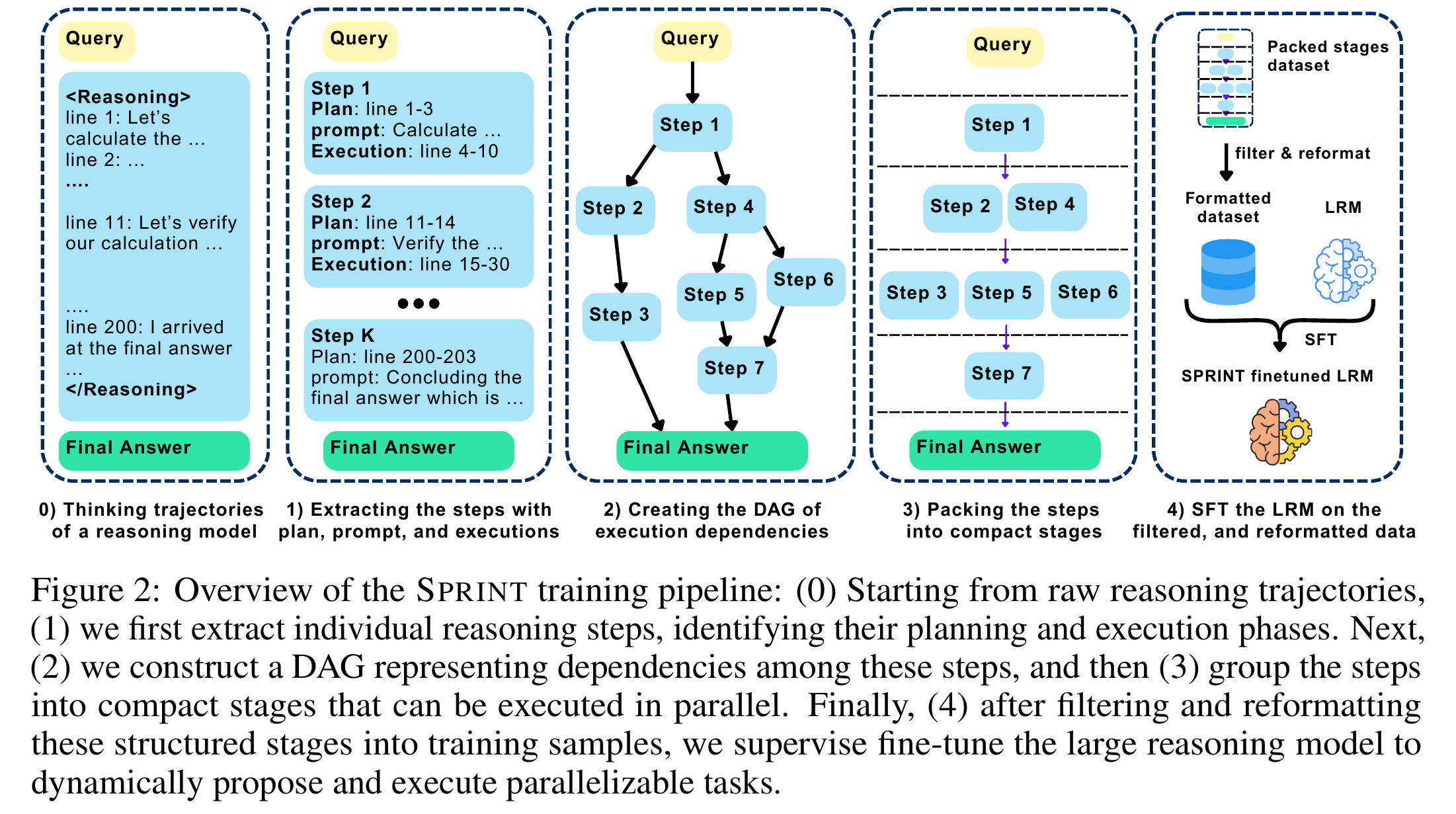
1.2 训练数据的构建(Data Curation Pipeline)
这是 SPRINT 最核心的技术贡献。普通的推理模型(如 DeepSeek-R1)生成的训练数据是线性的。SPRINT 设计了一套流水线,将这些线性思维链转化为并行的“规划 - 执行”结构。
具体步骤(如图 2 所示):
- 步骤提取 (Step Extraction): 使用 GPT-4o 将 R1 的长思维链分解为多个逻辑组件(Component)。每个组件被拆分为“规划(Plan)”和“执行(Execution)”两部分。
- DAG 构建 (DAG Creation): 使用 GPT-4o-mini 分析这些组件之间的依赖关系,构建一个有向无环图(DAG)。(例如:步骤 B 依赖步骤 A 的结果,但步骤 C 和 D 可以并行)。
- 打包 (Packing): 使用贪心算法将可以并行的步骤打包进同一个“阶段(Stage)”。
- 优化策略: 如果父节点只是纯规划(没有执行输出),子节点可以合并到同一轮次,以减少轮次。
- 过滤与重格式化: 筛选出那些具有高并行潜力(并行率 > 1.5)的数据,并将其格式化为
<Plan>…<prompt>…<execution>的训练样本。 - 监督微调 (SFT): 在这些重构的数据上微调基座模型(DeepSeek-R1-Distill-Qwen-7B)。
2. 创新点
- 动态交错规划(Interleaved Planning):
- 不同于 Skeleton-of-Thought (SoT) 这种一次性把所有骨架规划好的静态方法,SPRINT 是动态的。模型根据上一轮并行执行的结果来规划下一轮。这使得它能处理后续步骤高度依赖前序结果的复杂问题(如数学题)。
- 非启发式的并行化:
- 不同于 Tree-of-Thoughts (ToT) 需要预定义的搜索结构,SPRINT 是通过训练让模型自主学会何时该并行、何时该串行。
- 数据转化流水线:
- 提出了一套完整的方法,能够将现有的线性推理数据(Sequential CoT)转化为结构化的并行数据,这是解锁模型并行推理能力的关键。
3. 实验设置与结果
- 基座模型: DeepSeek-R1-Distill-Qwen-7B。
- 对比基线: 原始 R1 模型、RFT(在原始线性数据上微调的模型)、Skeleton-of-Thought (SoT)、Self-Consistency (并行采样)。
- 评估指标: 准确率 (Accuracy) 和 顺序 Token 数 (Sequential Tokens)。
- 顺序 Token 数 是衡量延迟的关键指标。对于 SPRINT,它等于:
SUM(每一轮中规划Token + 该轮中最长那个执行者的Token)。
- 顺序 Token 数 是衡量延迟的关键指标。对于 SPRINT,它等于:
3.1 主要结果 (MATH500 数据集)
- 准确率提升: SPRINT 达到了 92.5% 的准确率,不仅高于原始模型 (89.1%),也高于传统的线性微调模型 RFT (91.0%)。
- 原因分析: 并行执行让不同路径独立思考,减少了错误的累积传播(类似于集思广益)。
- 延迟降低: 平均减少了 440 个 顺序 Token。
- 长难任务表现更佳: 对于那些 RFT 模型需要生成超过 8000 Token 的复杂问题,SPRINT 减少了高达 39% 的顺序 Token。
3.2 泛化能力 (OOD 测试)
SPRINT 仅在 MATH 数据集上训练,但在其他领域表现出惊人的泛化能力:
- GPQA-Diamond (科学常识): 准确率与 RFT 持平,顺序 Token 减少 10.8%(长链推理减少 45%)。
- Countdown (算数游戏): 这是一个高度可并行的任务。SPRINT 准确率高达 85.9%,顺序 Token 惊人地减少了 53.5%(长链减少 65%)。
3.3 对比 Skeleton-of-Thought (SoT)
- SoT 在数学任务上表现很差(准确率仅 47.3%),因为它试图一次性规划所有步骤,忽略了步骤间的依赖性。
- SPRINT 证明了对于逻辑严密的推理任务,**交错式(Interleaved)**的规划是必须的。
4. 优劣势分析
优势 (Pros)
- 显著降低延迟: 在保持思维链质量的同时,大幅减少用户等待时间(尤其是复杂问题)。
- 保持通用性: 不需要针对特定任务写复杂的 Prompt 工程,模型自己学会了如何“分治”问题。
- 兼容性强: 这是一个 Post-training 框架,可以应用于任何已经经过 RL 训练的推理模型(如 Llama, Qwen, DeepSeek)。
- 准确率鲁棒: 并行执行实际上起到了类似 Self-Consistency 的纠错作用,避免了“一步错,步步错”。
劣势与局限 (Cons & Limitations)
- 硬件资源需求增加: 虽然时间(延迟)减少了,但总计算量(Total Compute)并没有减少,甚至可能因为 Prompt 的重复输入和 Overhead 而略有增加。要实现真正的加速,推理时需要多个 GPU 同时运行 Executors。
- 短任务的 Overhead: 对于非常简单、推理链很短的问题,引入规划和并行管理的 Token 开销反而可能导致总 Token 数增加(如论文中图 6 左侧所示,短任务增加了约 5%)。
- 实际部署难度: 论文中提到的“顺序 Token 减少”是理论上的延迟减少。要将其转化为实际的 Wall-clock time(墙钟时间)加速,需要复杂的系统工程(如 KV-Cache 共享、高效的 GPU 调度),这在论文的“局限性”章节也提到了。
- 数据依赖: 该方法依赖于 GPT-4o 这种强模型来清洗数据构建 DAG,成本较高。
5. 总结
SPRINT 是一项非常有前景的工作,它打破了思维链必须“线性生成”的固有范式。通过模仿敏捷开发的流程,让大模型学会了像人类团队一样:先规划,分头行动,再汇总,再规划。这不仅提升了推理效率,也为未来在受限时间内进行超长思维链推理指明了方向。