In this work, we argue that advancing interleaved generation requires a unified Reinforcement Learning (RL) framework that jointly optimizes text and image generation policies.
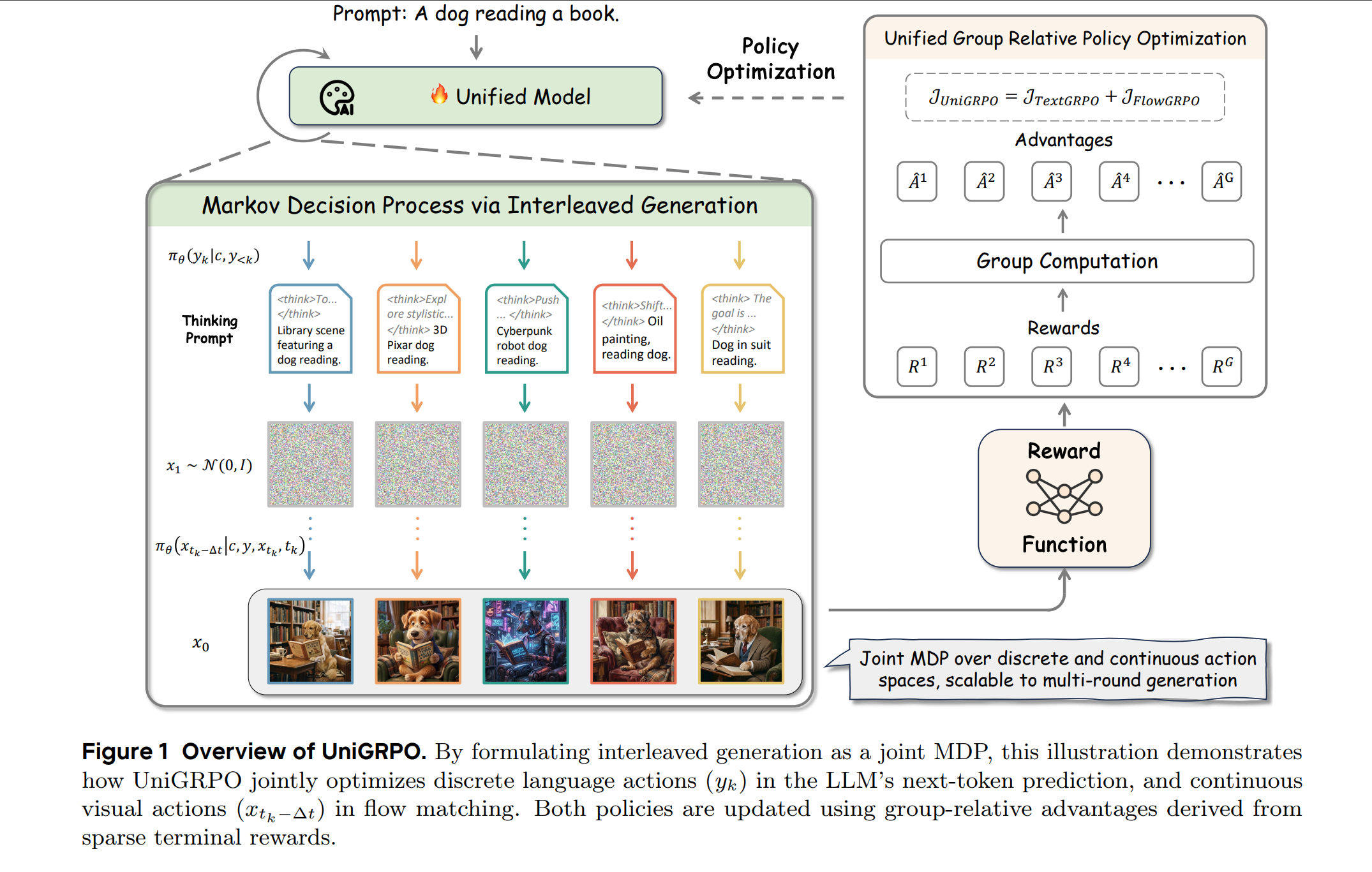
Methods
相较于 FlowGRPO,UniGRPO 主要有如下几点不同:
去除 CFG
由于在多轮文图交错中使用 CFG 会造成计算量翻倍且生成轨迹出现分支,因此 UniGRPO 直接去除了 CFG,使得整条轨迹重新变为线性的,降低计算复杂度和显存占用
CFG:
在 UniGRPO 中取
速度场 MSE 损失代替 KL 散度
在 FlowGRPO 中引入了 KL 散度来避免 reward hacking,然而在不同时间步 上,加噪程度不同,KL 散度项的权重有复杂的变化,可能会被 RL 训练捕捉并利用(造成类似 reward hacking 图像崩坏)的情况。
因此 UniGRPO 选择直接对速度场求 MSE 损失,显式控制优化范围。虽然丧失了完全严谨的理论推导,但是更能避免 reward hacking
统一损失
将整条轨迹视为一条 MDP,并计算相同的一个损失: