PPO
共有四个模型:
- Policy model (Actor model)
- 一般由 SFT 模型初始化,不断进行参数更新
- Reference model
- SFT 模型初始化,参数冻结
- Reward model
- 使用 SFT 模型初始化并添加一个回归输出层,然后微调得到
- 在 RL 训练中被冻结
- 对 policy model 输出的 token 进行奖励评分
- Critic Model (Value model)
- 对当前 policy model 输出的 token 估计其未来奖励期望
- 尽可能地使得策略模型能够生成不仅即时奖励高,而且对未来奖励收益高的 token,本质就是给出广义优势估计
- 在强化学习过程中需要参与参数更新
算法流程(policy model , critic model ):
- 收集数据 ,对应打分 ,其中 .
- 对每条数据,计算每个时间步 的折扣累计回报
- 实际使用 迭代计算
- 对每条数据,计算每个时间步 的优势估计值
- ,其中
- 用于控制估计的偏差 - 方差之间的权衡, 为蒙特卡洛,高方差低偏差; 为 TD(0),高偏差低方差
- 更新 policy model 和 critic model:
- 熵奖励
- 总损失函数 ,一般
技巧:
- 重要性采样:
- Clip 机制: 时,需要 更大,通过 约束;反之类似。 用于采纳更保守的一项作为优化目标
优点:
- 稳定性高:clip、KL penalty
- 易于实现,超参数相对少(相较于 TRPO)
缺点:
- 训练成本大
- Clip 机制丢弃大量梯度信息
- 样本数据利用率低:on policy 架构,引入 off policy 技巧
- 超参数敏感
DPO
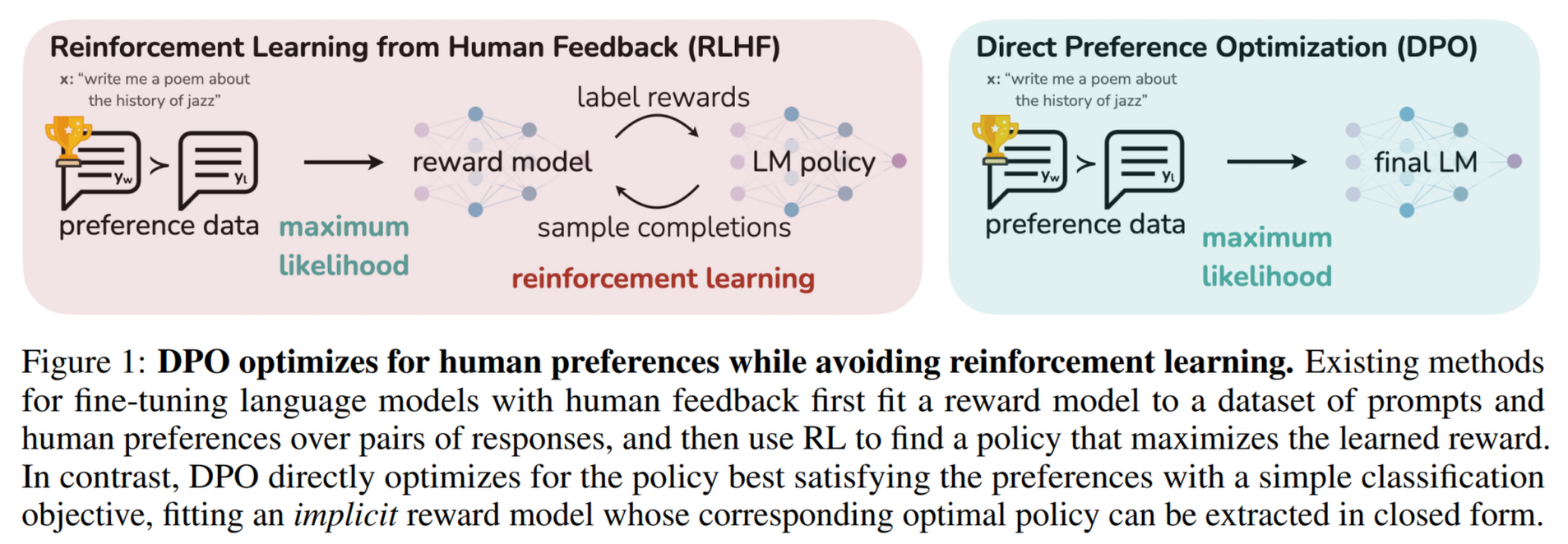
直接偏好对齐,用于解决 PPO 训练难度大、不容易收敛、资源消耗大的问题。方法为:通过二元交叉熵直接拟合人类偏好数据。
公式:
优点:
- off policy:直接拟合预先准备好的人类偏好数据
- 资源消耗低:只需要 policy model 和 reference model,无需 reward model 和 value model。甚至可以提前录好 reference model 的结果进一步减小资源消耗。
- 有监督学习:通过概率匹配直接优化策略,因此稳定性高、训练难度低(只需关注学习率和偏好权重
缺点:
- 容易过拟合:缺少了 reward model 的泛化
- 更依赖数据标注量,从而还导致多任务适配较难(需要给每一个任务进行大量标注)
推导
在 RLHF 中,目标函数为
其中 为奖励函数, 为控制 KL 惩罚力度的系数。可以证明有一个封闭形式的最优解:
DPO 则使用这个公式反解出 为:
在偏好建模中,通常假设人类选择 优于 的概率符合 Bradley-Terry 模型(即 Sigmoid 函数):
则
进而就可以得到 。同时也可以知道,DPO 中的 实际上用来控制 KL 惩罚, 越大则模型越不关注 KL 散度约束,更激进地拟合偏好数据(容易过拟合或退化);反之则训练更保守。
为什么不直接使用线性相减作为损失?
首先是从上面的推导出发可以说明不能用线性相减。其次从优化角度来说,DPO 的形式 对应的梯度为 ——当 非常小时,会有一个 的惩罚,而当 非常大时( 显著好于 ),梯度更新为 ,模型基本不会进行更新(软截断机制)。
而如果使用线性相减的形式 ,则梯度始终为 ,模型不论如何都会去拟合更偏好的答案,更容易过拟合甚至训练崩溃
DPO 会出现 Reward Hacking 吗?
会。首先需要明确 DPO 是有(隐式)奖励的:
- 概率比值爆炸:模型可能会通过生成 reference model OOD 的回答來获得极小的 ,从而获得极高的奖励
- 生成重复啰嗦的回答:同 1
- 偏离漂移: 较小时, 过分偏离 ,导致输出质量下降
GRPO
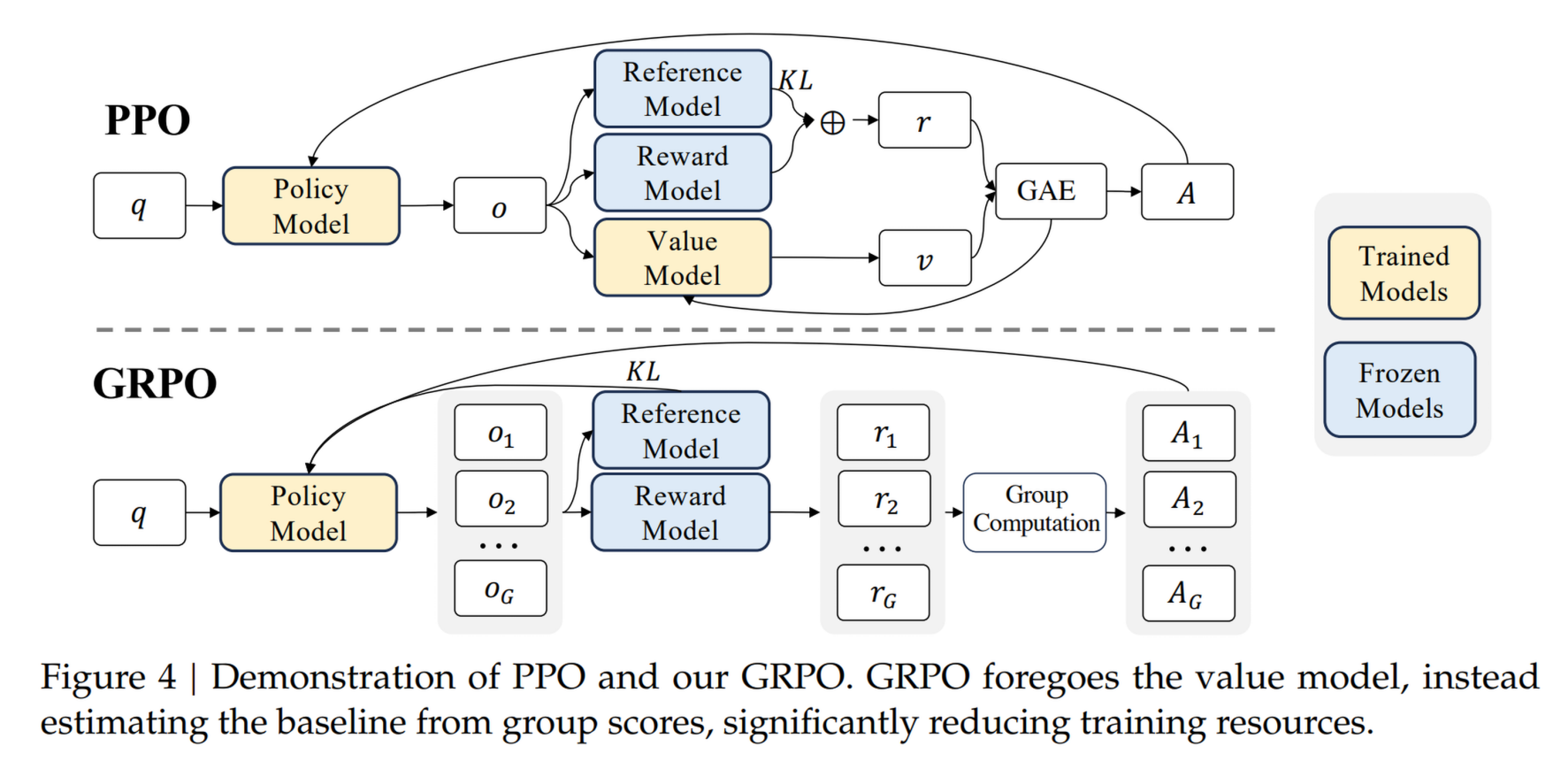
目标函数:
优点:
- 没有价值函数的依赖,提升稳定性
- 更低的训练难度和训练成本:不需要 PPO 中的 critic model (value model),reward model 也能够被替代
- 更强的探索能力:一组策略就是在并行探索不同区域,避免单个策略陷入局部最优
- 实现简单且易于并行训练
缺点:
- 计算复杂度高,有新的超参
- 高方差和训练不稳定:在 token 级别上进行重要性采样,但是每个 token 只会被采样一次,很难做到有效的分布校正,引入了高方差的噪声
- 奖励函数目标和优化的目标不一致问题: 是通过序列级优势计算出的,但是却用在了 token 级别的优势上。例如如果一个 token 是非常错误的,在 上的概率只有 ,但是却被 以 的概率采样到了,这会导致 的量级在 级别,极大的引入了噪声。后续 GSPO 在此基础上进行了优化
PPO 和 GRPO 分别属于 MC 和 TD 算法中的哪一种?
PPO 实际上属于基于 TD 算法的 Actor-Critic 框架。这从它的 GAE 项可以看出来:。
而 GRPO 通过大量采样统计实际结果,不依赖价值函数 ,故而是 MC 算法。
另外,GRPO 只有在整条数据都生成后才能进行更新,符合 MC 算法的特征。
我们由此还能知道,PPO 偏差较高 (依赖 Critic 准确度) 而方差较低,GRPO 偏差无 (无偏估计),方差较高 (依赖采样数量)
GRPO 为什么加上 KL 散度,用的 KL 散度是正向 KL 散度还是反向?
GRPO 中使用 KL 散度以避免模型更新后和初始模型差异过大。使用反向 KL 散度。
首先需要知道正向 KL 散度和反向 KL 散度的区别:假设 是参考分布, 是近似分布,由于 KL 散度的不对称性:
正向 KL 散度中 :若在 并非很小的地方 非常小,则该项值会非常大,会被最小化给“修正”。带来的结果是近似分布 的高峰区域会尽可能覆盖 的所有高峰区域。
同理可以知道, 的低概率区域会覆盖 的低概率区域,因此 会更倾向于只覆盖 的少数高峰区域。
在做分类任务(Cross Entropy Loss)时,实际上就是在最小化正向 KL。我们希望模型能够覆盖所有训练数据(真实分布 )的情况。而在 RLHF 中,我们希望生成的回答()一定是通顺的、符合参考模型()逻辑的。与其让模型输出一堆乱码去尝试覆盖所有可能,不如让它锁定在一种高质量的输出模式上。
具体怎么计算 KL 散度,KL 散度和交叉熵的关系是?
在 veRL 中,KL 散度有三种方式进行近似,见 veRL 源码 —— actor 是如何更新的,如下:
模式配置 Forward 数值 (Reward 计算) Backward 梯度 (参数更新) 备注 "k1"/"kl"同 Forward 标准做法,方差大 "k2"/"mse"同 Forward 梯度稳,数值近似 "k3"同 Forward 数值稳,梯度可能有偏 "k3+"(推荐)(K3) (K2) 数值用 K3,梯度用 K2 其中 k3+ 方法结合了 k3 在数值期望上准确,但是在期望梯度上不准;同时 k2 虽然在数值期望上不准,但是期望梯度上准确的性质,通过
backward_score - backward_score.detach() + forward_score.detach()的方式,巧妙实现了前向和反向传播的同时正确性。
另外,交叉熵是正向 KL 散度。
为什么 GRPO 和 PPO 都要对 再取一个 min,而不是直接用
对 的样本,如果其更新幅度较小(),则会依然保留更小的 ,保留了梯度;而如果更新幅度过大(),则 会被截断为 ,没有梯度贡献了。在 veRL 中,这里的截断是使用
torch.clamp函数。对 的样本,如果其更新幅度较大(),则会依然保留更小的 ,保留了梯度;而如果更新幅度过小(),则 会被截断为 ,没有梯度贡献了。
综上可以知道,使用 的原因是 (1) 对于正样本,不要过于自信的进行更新 (2) 对于负样本,尽可能的进行惩罚,但如果新模型 在参考模型的高峰区域采样到了低概率 token,则说明该 token 很可能是噪声,需要进行屏蔽。
GRPO 训练时出现提前收敛的现象,即一个 epoch 尚未训练完成,reward 就已经饱和,这种情况有什么处理思路
- 调参:学习率调小、batch size 调大、rollout size 调大、KL 惩罚调大、warm up step 合适
- 检查数据分布,是否有 shuffling
- 检查 reward score 分布范围和 KL 散度的 scale 是否一致,否则 loss 可能会被 reward 主导,导致和 reference model 的偏差过大
GRPO 能否使用 off-policy 的数据辅助 reward 计算? 例如同一个 query,使用几个 step 之前的 rollout,以降低采样压力?
不行。因为在计算优势 时,公式为 ,如果使用旧策略的 rollout,则 和 的估计都是有偏的,则 的计算就是不准确的。另外在训练初期,rollout 质量往往很差,会很大影响训练进度
DAPO
这篇文章讲得很详细了:https://zhuanlan.zhihu.com/p/31157035727.主要有这几个 trick:
- Clip higher:提高 的值
- 原因是训练中熵会迅速降低,且低概率的 token 受 的影响更大( 时,更新前后概率 ,显然低概率 token 的最大可能概率几乎没有变化,从而限制了模型的探索
- Dynamic sampling
- 当一组回复的值全相等的时候,优势为 0,而根据 ,可知该组对应的梯度也为 0,所以不如直接舍弃这部分样本
- Token 级策略梯度损失:同 Dr.GRPO
- Overlong Reward Shaping:如下面的公式所示
- 移除 KL 散度
Lite PPO
做了大量实验,然后归纳出如下两个有效 trick,从而得到 Lite PPO 算法:
- 组级别均值 + 批次级别标准差
- Token 级别损失聚合:同 Dr.GRPO
Dr.GRPO
目标函数:
这里 . 相较于 GRPO 有两个变化:
- 去除了 GRPO 序列的归一化(),这是因为虽然这样会使每一个序列的 loss 归一化,但是在进行更新时,梯度也会被除以 ,导致正确的()且较短的样本,以及错误的()且较长的样本的每一个 token 的梯度更大
- 去除了优势中的分母 。原因是作者认为 的存在会使较难和较简单的样本的优势过于放大
GSPO
相较于 GRPO,计算的是整个序列的重要性采样比率:
相应的损失为:
注意剪裁也变成了序列级的剪裁。
优点:
- 对 MoE 架构的模型友好:同一批样本输入 MoE 模型,激活的专家网络都可能不一致,导致计算出的 有较大波动,触发 clip 机制损失梯度信息,又本身噪声很大。GSPO 在序列角度计算重要性采样,对 token 级的重要性比值波动不敏感
- 训练稳定性高:在 GRPO 中讨论过
缺点:代码实现稍显复杂
GSPO 计算序列重要性采样为什么用几何平均值,不用算数平均
- 几何平均对极端值不敏感, 极大或极小时都不会受很大的影响(因为有开 次方根的操作)
- 符合序列建模:
其他面经
强化学习中如何判断是否出现 reward hacking,有什么解决思路
判断的核心是 reward score 和其他指标或表现有无矛盾的地方:
- reward score 上涨,但 eval score 无明显变化甚至下降
- KL 散度过高,说明偏离了 reference model 过多
- response length 过长,常见于有长度偏见的 reward model
- 复读现象严重,重复某些特定的高分词汇、短语,或者不断重复用户的 Prompt
解决思路:
- 重新设计 reward,如长度约束、复读惩罚等,还可以在训练过程中更新 reward 给法
- 加 KL 散度约束
- rollout 出的样本中,过滤掉
old_log_prob过小的样本(偏离 reference model 太多)
大模型的强化学习训练时出现 entropy collapse,有什么解决思路
- 调整 KL 惩罚
- 调整熵正则化项,但是需要注意在大模型中由于词表太大,过大的熵系数会导致模型倾向于输出均匀分布的“乱码”来最大化熵,而不是生成有意义的多样化文本。建议退火或者不要使用
- 调整奖励模型/规则
- 调整采样策略:提高采样温度(),收集多样性更强的数据;同时调整
top-p和top-k來过滤长尾低质量 token- 检查数据的质量
Reference
- 大模型强化学习-PPO/DPO/GRPO区别对比
- PPO、DPO、GRPO、GSPO算法的万字详解
- DAPO:字节完整开源全部复现RL细节
- [2305.18290] Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- [1707.06347] Proximal Policy Optimization Algorithms
- [2402.03300] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- [2507.18071] Group Sequence Policy Optimization
- [2503.14476] DAPO: An Open-Source LLM Reinforcement Learning System at Scale
- [2508.08221v1] Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning
- [2503.20783] Understanding R1-Zero-Like Training: A Critical Perspective
- [面经记录]LLM+RL 50问