Overview
想要将 GRPO 应用于 flow matching,有两个难点:
- flow model 依赖于确定性的 ODE(),而 RL 依赖于随机性的采样以探索环境。两者存在天然冲突
- RL 训练需要高效的 sampling 来收集训练数据,但是 flow model 每次采样都需要多次迭代,并不高效
Flow-GRPO 提出两种方法来解决如上问题:
- 使用 ODE-to-SDE 策略将 flow model 的 ODE-based flow 转化为等价的 SDE 框架(注意训练时使用的是 SDE,而推理时仍然使用 ODE)
- 使用 Denoising Reduction 策略将去噪步骤减少,同时保持生成质量
总之,有如下三点贡献:
Summary
- We are the first to introduce GRPO to flow matching models by converting deterministic ODE sampling into SDE sampling, showing the effectiveness of online RL for T2I tasks. Flow-GRPO improves SD3.5-M accuracy from 63% to 95% without noticeably compromising image quality.
- We find that online RL for flow matching models does not require the standard long timesteps for training sample collection. By using fewer denoising steps during training and retaining the original steps during testing, we can significantly accelerate the training process.
- We show that the Kullback-Leibler (KL) constraint effectively prevents reward hacking, where reward increases at the cost of image quality or diversity. KL regularization is not empirically equivalent to early stopping. With a proper KL term, we can match the high reward of the KL-free version while preserving image quality, albeit with longer training.
Methods
ODE SDE
通过数学推导,作者将确定性的 ODE
转化为了
这里 代表 Wiener process increments,而 代表随机程度( 越大,diversity 越高)。对于 rectified flow,上式变为:
再对上式应用 Euler-Maruyama 离散化,得到
其中, 表示随机程度。在 paper 中,作者使用 , 为超参数,代表 noise level。这个式子说明, 服从各向同性的高斯分布
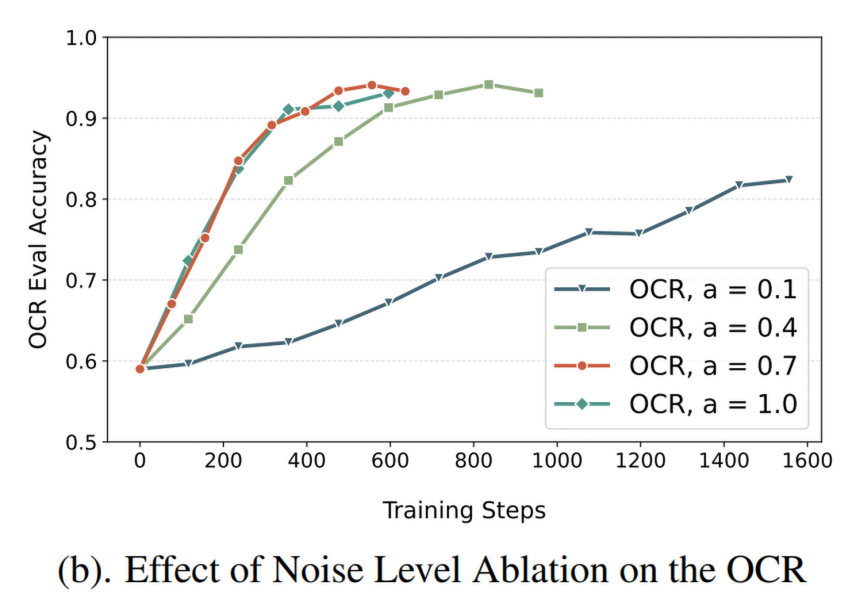
在从 0.4 到 0.7 前增长,效果也随之增长,直到 0.7 后变化不大
另外可以计算出 和 之间的 KL 散度:
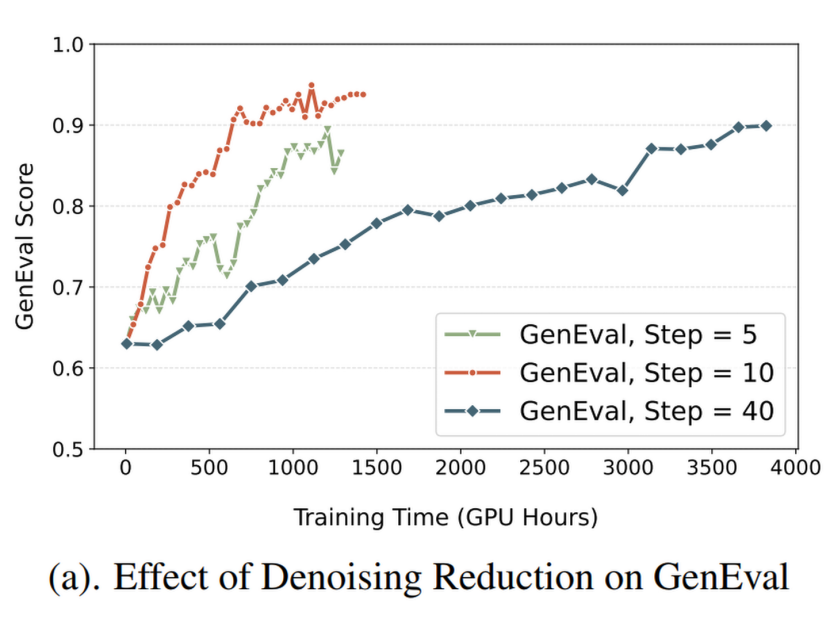
Denoising Reduction
作者发现较大的 timesteps 在 online RL training 中是不必要的,因此在训练中设置 ,而在推理时保持 (SD3.5- 的默认值)
疑问:会不会造成训推不一致的问题
作者在去除 kl constraint 的条件下调整 值,发现从 40 降至 10 时,能有效提升训练速度且不降低指标,但是进一步降低至 5 时,并不能一直提速,反而有时候会更慢
KL Regularization
实验发现,通过调整 kl 系数,在训练过程中将 kl 散度保持在一个较小的常量值(即保持在原始模型参数附近),能够有效缓解 reward hacking,结果如下图 2,在 CIG 和 VTR 任务上都有明显提升;同时在 HPA 任务上,虽然指标没有明显下降,但是生成的图片的多样性有明显下降
Integration with GRPO
给定一个 prompt ,flow model ,采样一组 个图像 以及对应的反向时间轨迹 。每个图像的 adv 如下:
GRPO 最大化如下目标:
这个式子里面, 已经有公式可以用于计算, 则通过高斯分布的特性进行计算
NOTE
实际上,Flow-GRPO 优化的方向是 advantage-weighted noise,参考 https://zhuanlan.zhihu.com/p/1994761798193288744
Experiment Results
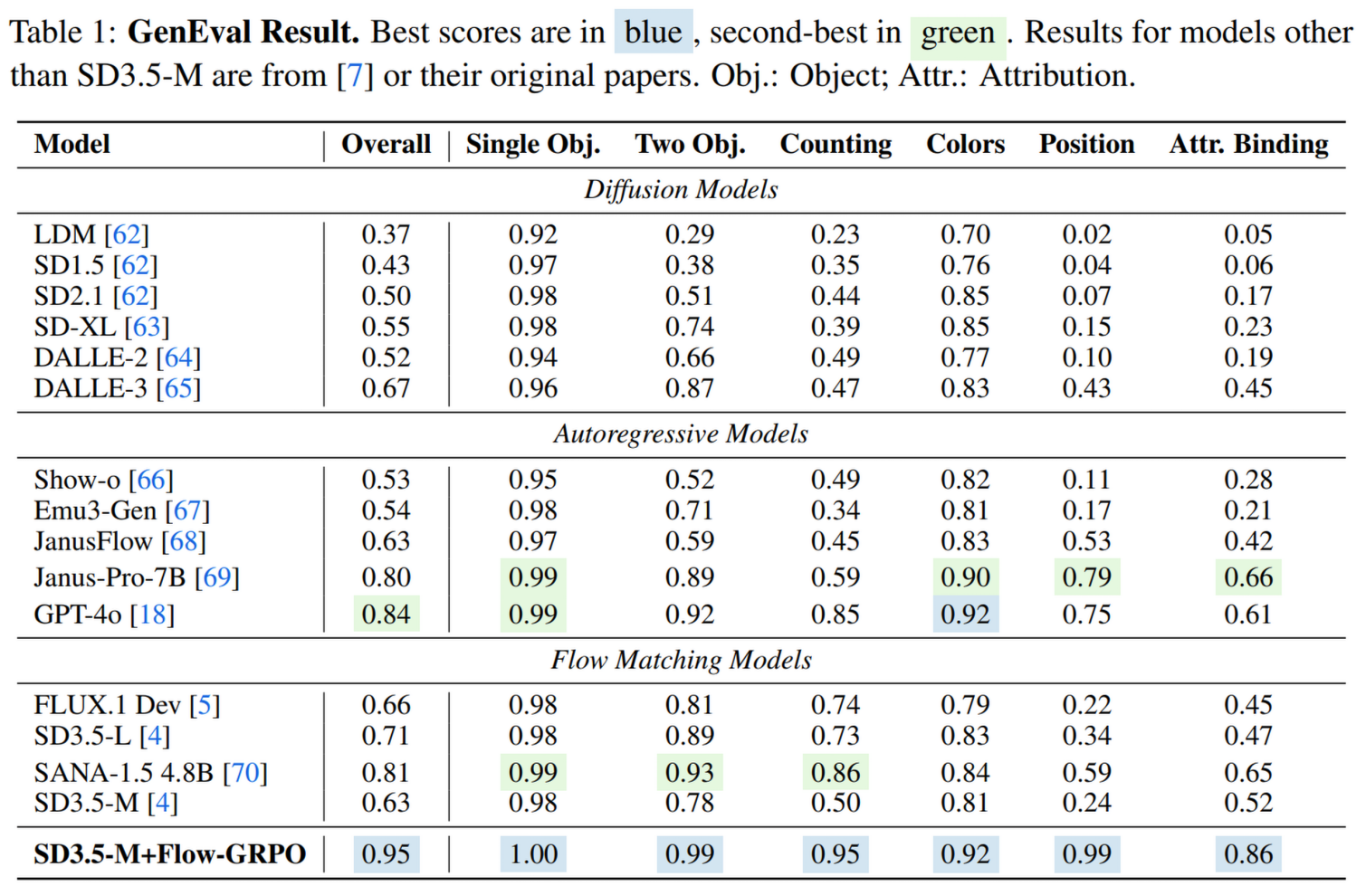

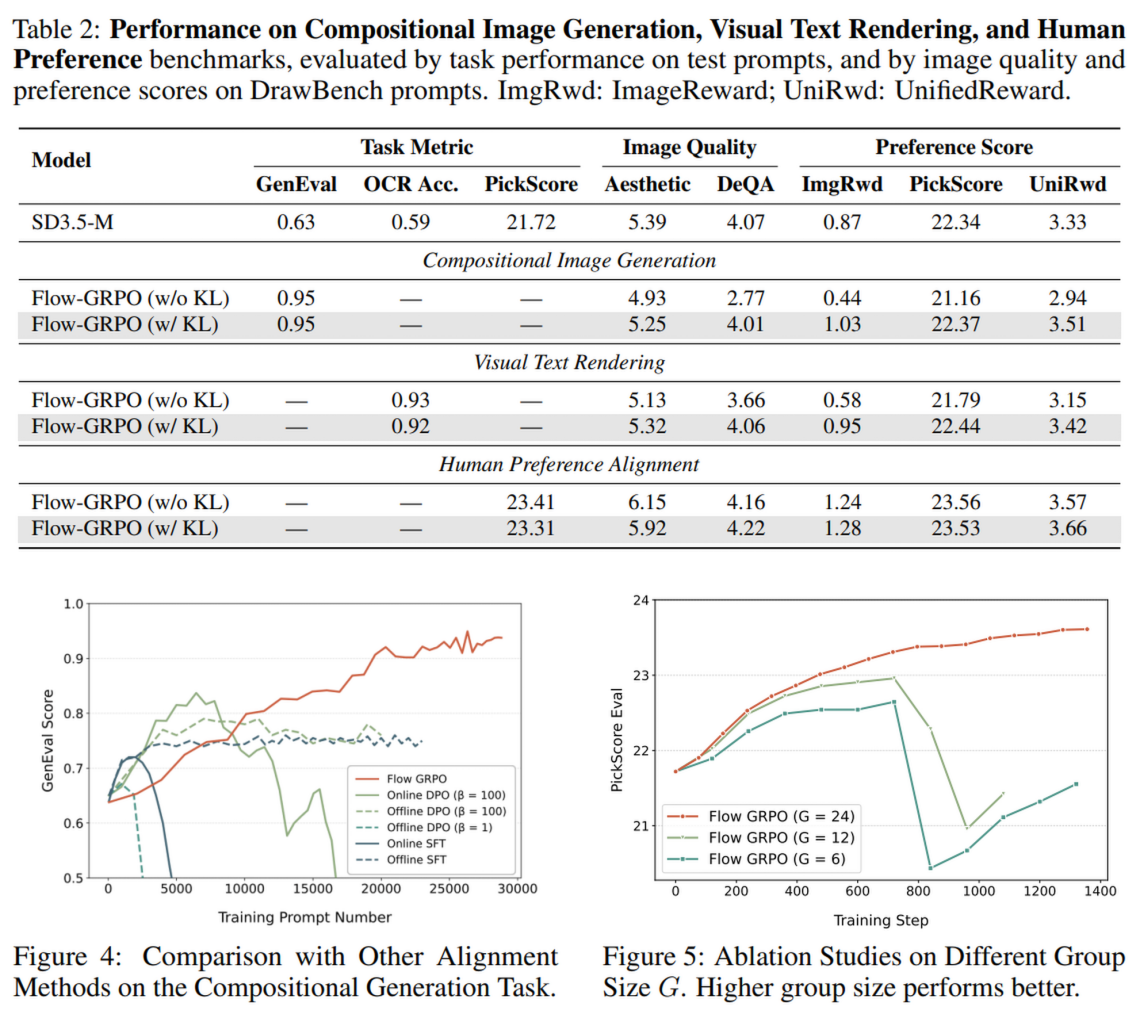
Reference
- [2505.05470] Flow-GRPO: Training Flow Matching Models via Online RL
- 视觉生成 RL 模型解读 (一):Flow-GRPO:第一个使用在线 RL 的 Flow Matching 生成模型
- Flow Matching RL(一):Flow-GRPO在学什么?
更进一步地,想要了解 Flow-GRPO 生成图像带有过多噪声的原因以及其改进方案可以阅读:https://zhuanlan.zhihu.com/p/1948388095151026330
另外推荐一个知乎系列文章:视觉生成超详细解读 (目录)