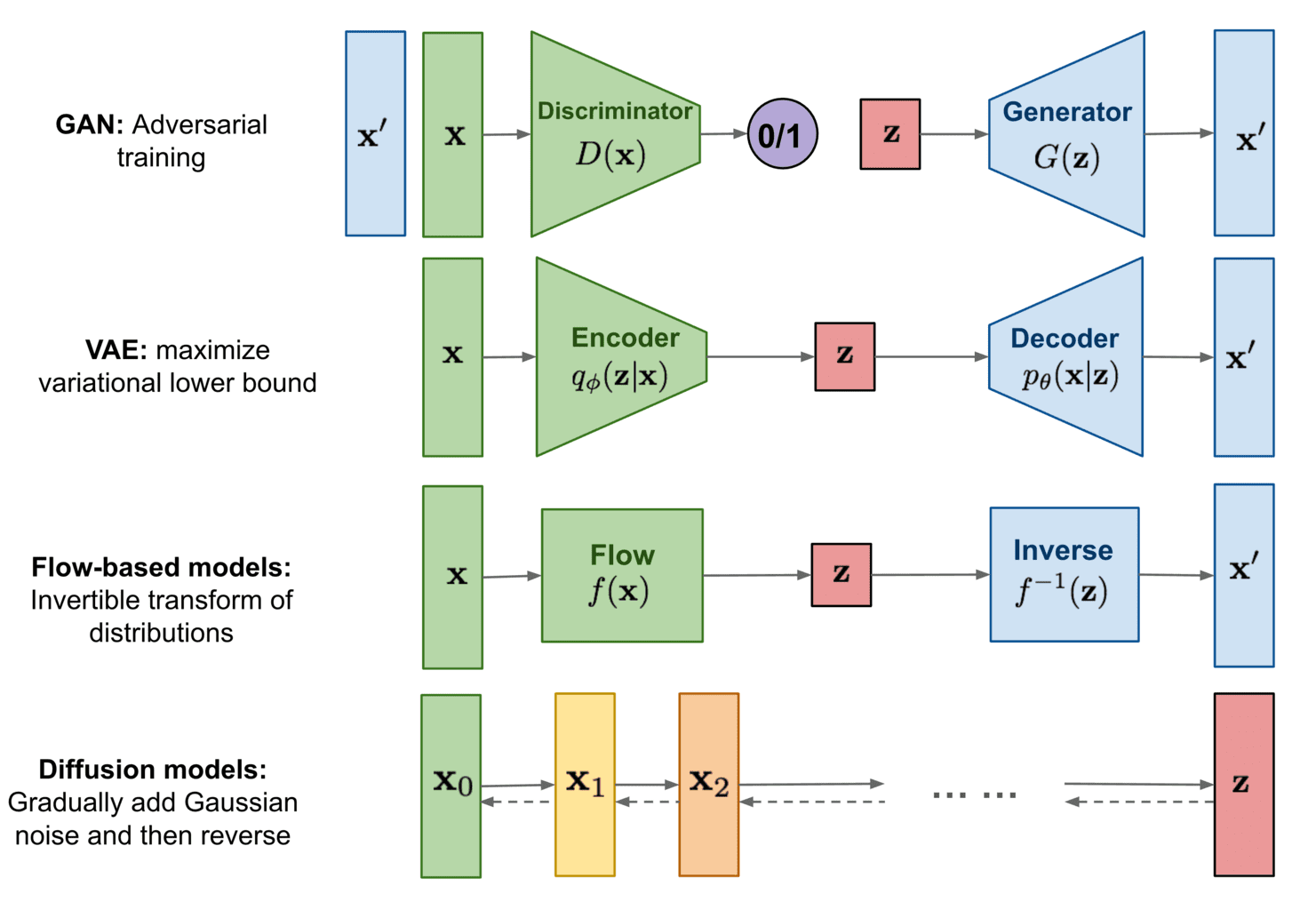
Generative Model
四种 DL-based 生成模型:
- Variational Autoencoders (VAE)
- Flow-based models
- Generative Adversarial Networks.
- Diffusion
这四种模型都有其缺点,如下图:
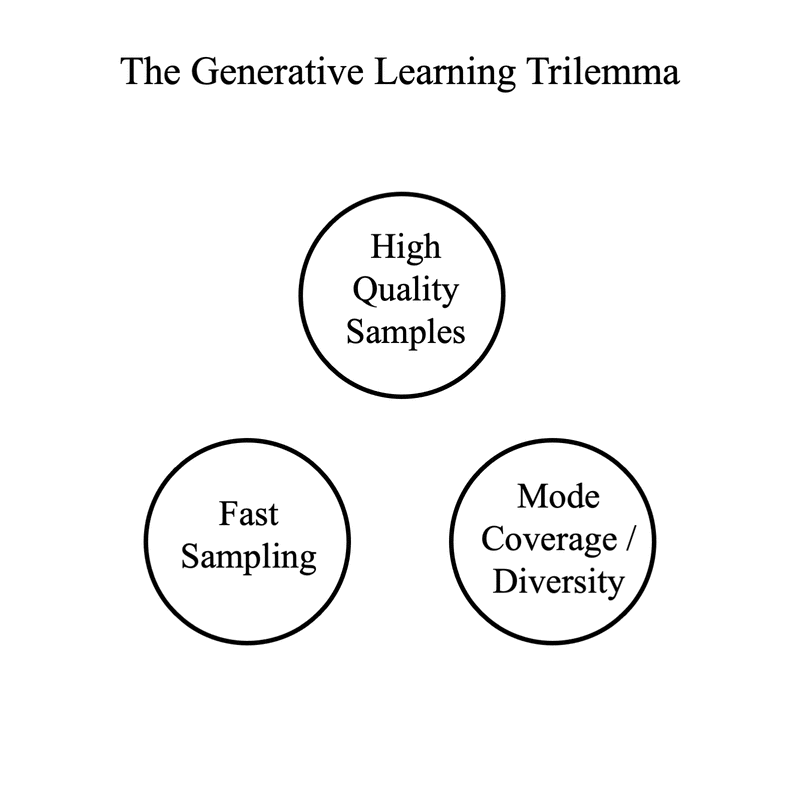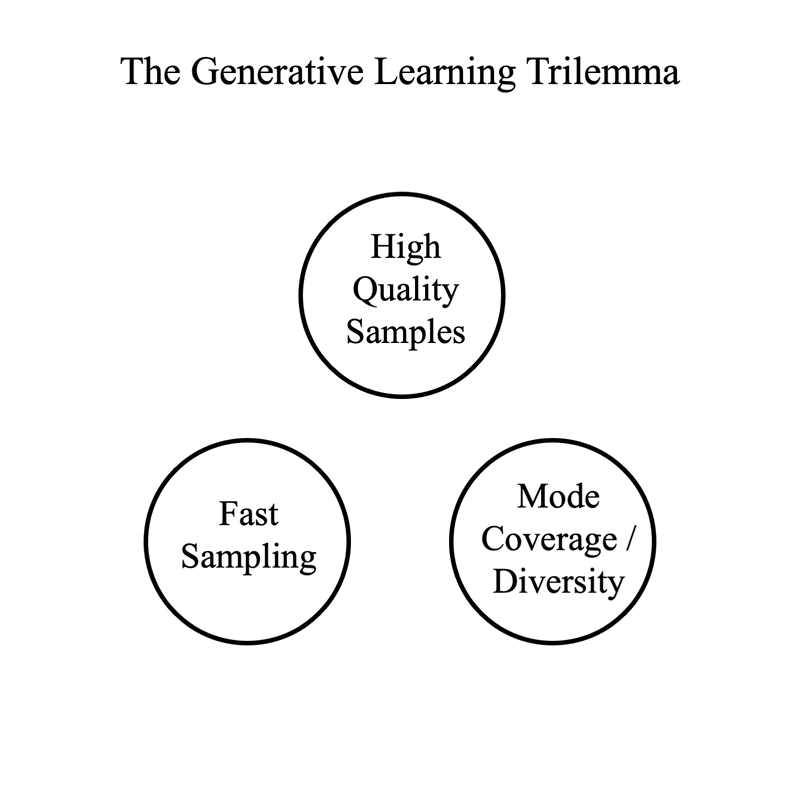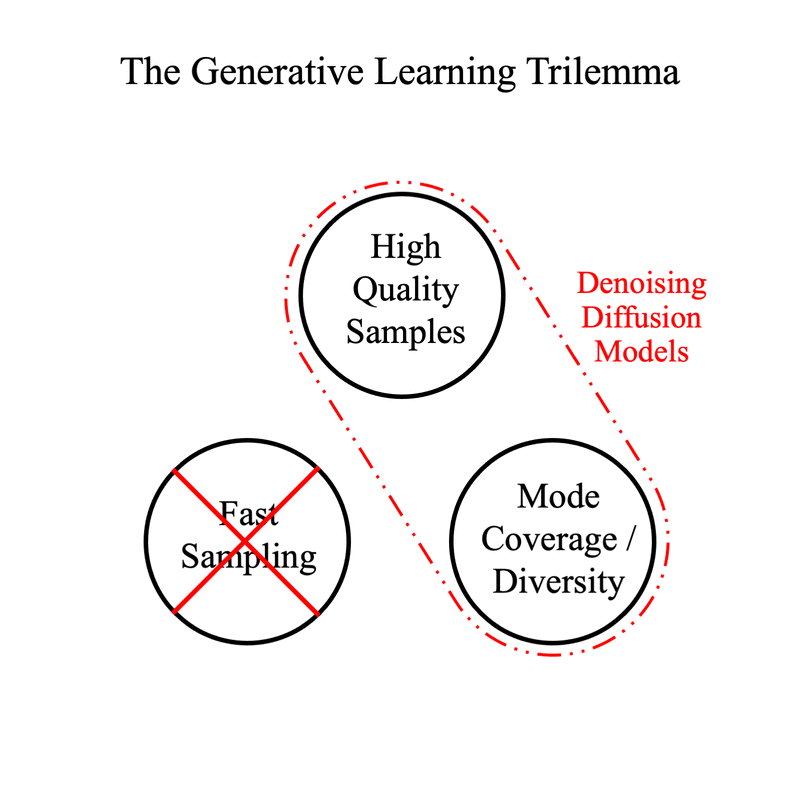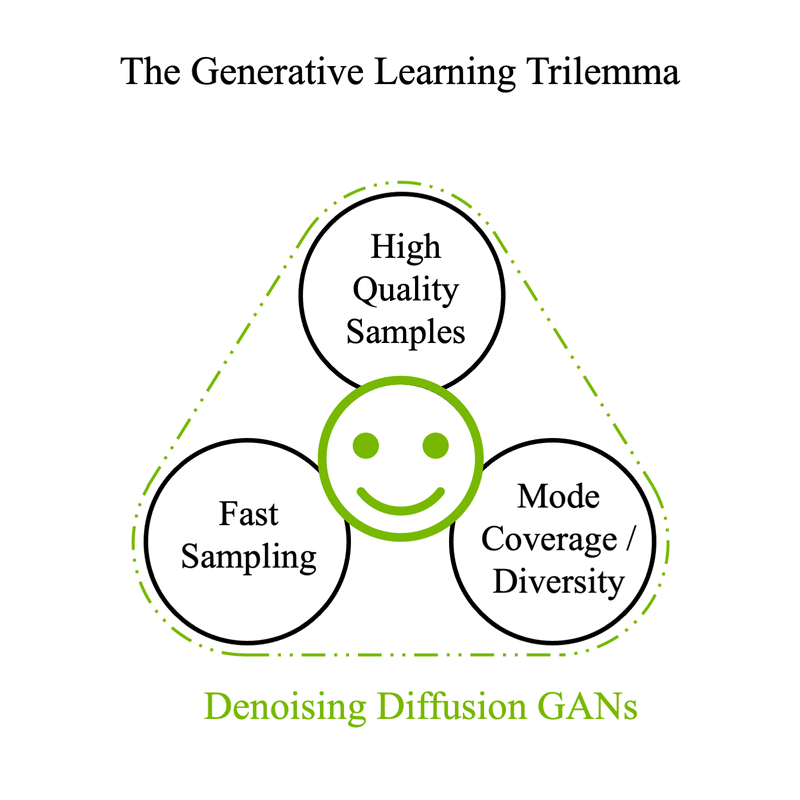
| VAE | FLOW | GAN | Diffusion | |
| Pros | Fast Sampling rate. Diverse sample generation | Fast Sampling rate. Diverse sample generation | Fast Sampling rate. High sample generation quality. | High sample generation quality. Diverse sample generation |
| Cons | Low sample generation quality | Need specialized architecture, low sample generation quality | Unstable training, low sample generation diversity (Mode Collapse) | Low sampling rate |
Diffusion Model
主要思想
…systematically and slowly destroy the structure in a data distribution through an iterative forward diffusion process. We then learn a reverse diffusion process that restores structure in data, yielding a highly flexible and tractable generative model of the data. This approach allows us to rapidly learn, sample from, and evaluate probabilities in deep generative models …
- Forward 过程(data to noise):
- 原始图像
- 重复 次加噪:,最终得到
- 无模型参与
- Backward 过程(noise to data):
- 有模型 参与:
DDPM
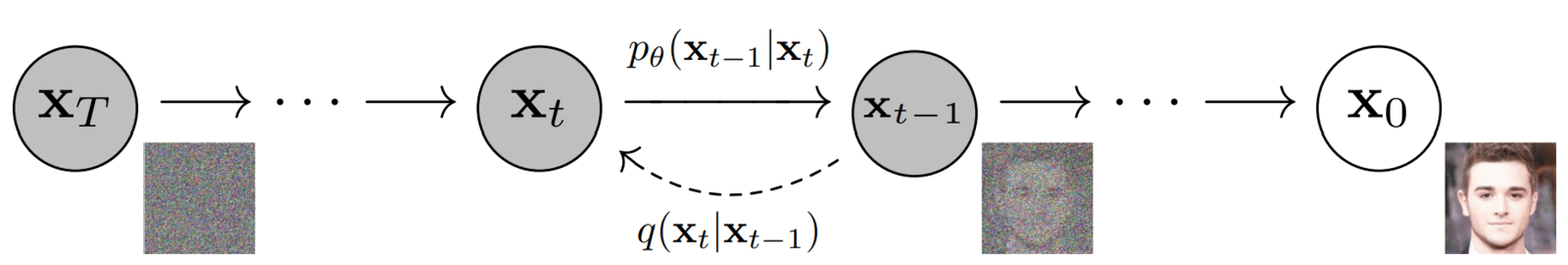
NOTE
DDPM 是 Diffusion Model 的一个子类,其特点在于:
- 预测噪声而非预测图像: 广义的扩散模型可以尝试在每一步预测上一张稍微清晰一点的图片。但 DDPM 发现,让神经网络(通常是 U-Net 架构)直接去预测当前图片上被添加了多少噪声(),效果出奇的好,数学优化上也更加稳定。
- 固定的加噪过程: DDPM 使用了基于马尔可夫链(Markov Chain)的设定,规定了每次加噪的幅度(Variance Schedule)是预先设定好的、固定的,不需要模型去学习,这大大降低了训练难度。
- 简化的损失函数: DDPM 的作者通过巧妙的数学化简,去除了复杂的变分下界(VLB)中一些难计算的项,得到了一个极其简单、优雅的均方误差损失函数(MSE)。模型只需要比较“真实的噪声”和“预测的噪声”的差异即可。
Forward 过程
这个系数是如何确定的
答案是为了保持方差。重参数化 为 ,则 的方差为:
假设 已经是一个近似方差为 的分布,且 与新加入的噪声 是相互独立的,根据方差的性质:
这是最终 能够顺利的收敛到 的必要条件
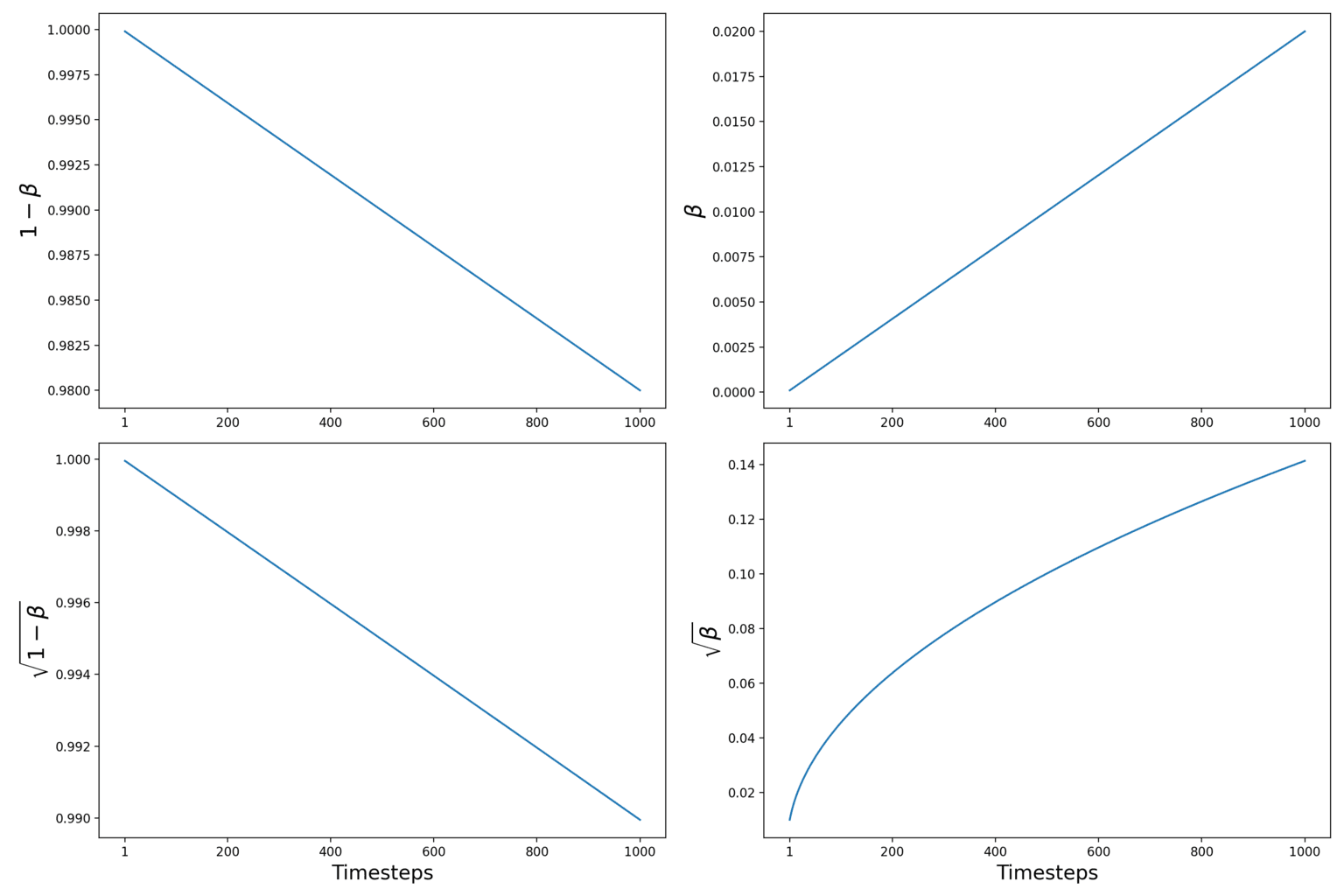
在实际使用时,DDPM 的作者让 取值为 ,总步数 ,使用线性取值,如下图:
为了解决“获取 就需要前向 次的问题”,可以通过数学推导来求解,即求解 :
这里 且相互独立,则有
记 ,则
再记 进而
同理可以得到
如此便可以一步得到 ,而无需反复进行前向过程
Backward 过程
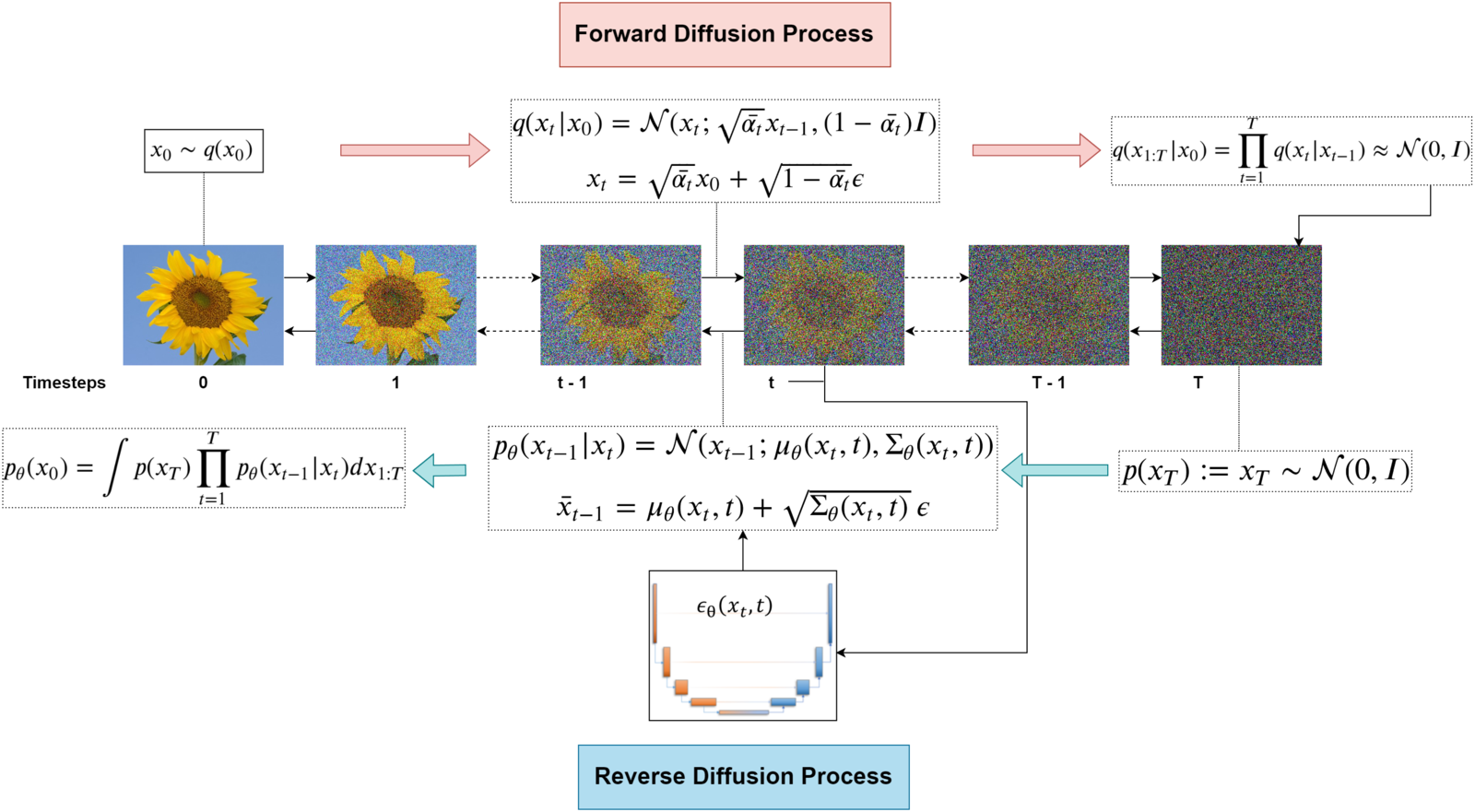
(图片中 有误)
In 1949, W. Feller showed that, for gaussian (and binomial) distributions, the diffusion process’s reversal has the same functional form as the forward process. 这意味着可以假设后向过程 也遵循高斯分布
我们需要求得一个模型 ,即 ,由上面这段话,可以假设
Loss Function
设计 loss 的 insight 为“最大化反向过程中生成的 在原始数据分布中的 log-likelihood”,即
这一点和 VAE 是相同的,可以仿照 VAE 引入变分推断的方法,即引入
NOTE
回忆 VAE 中推导 loss 时,引入了 。在 diffusion model 中, 可以视为 VAE 中的隐变量
而
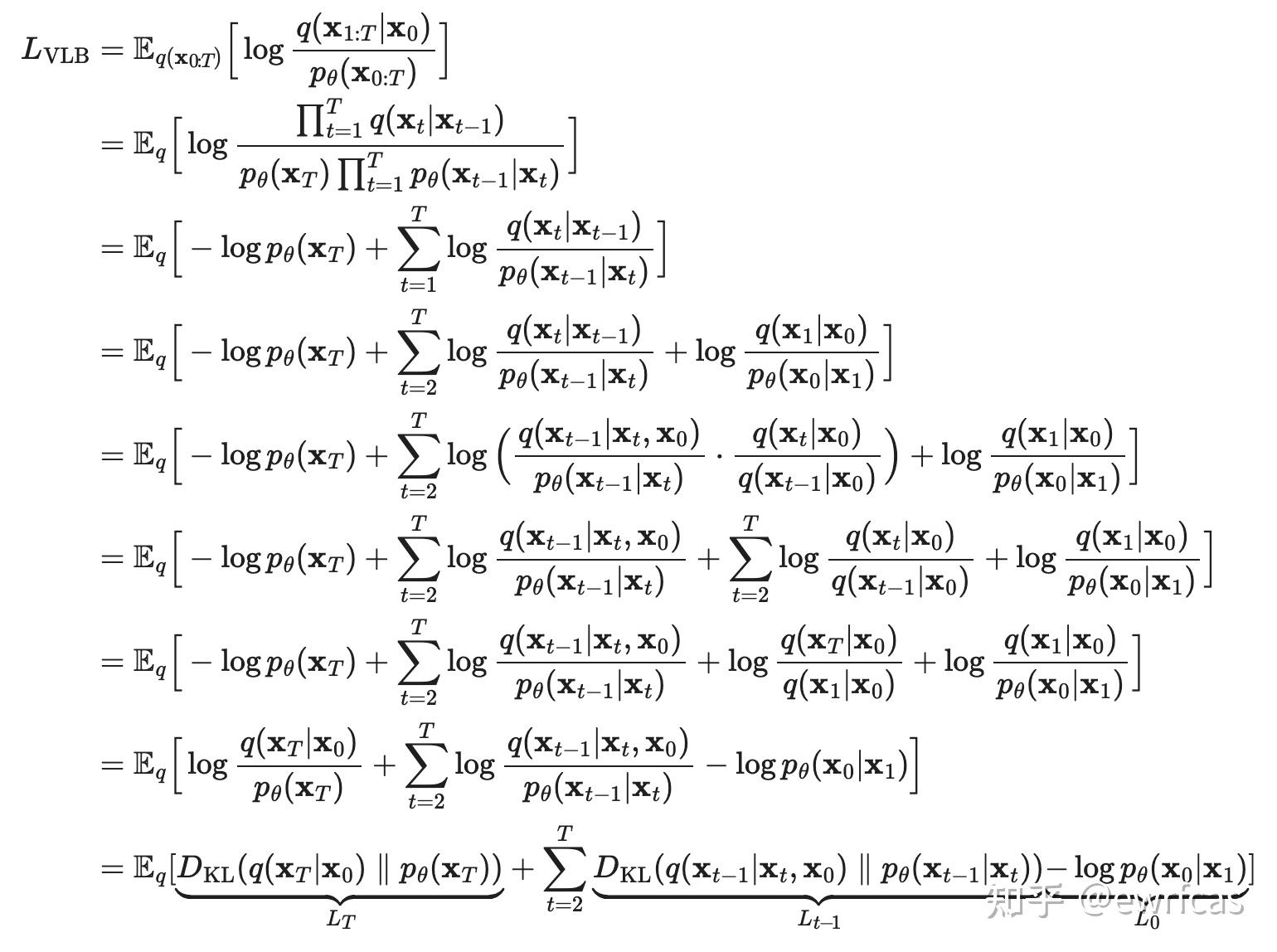
可以将 loss 总结为:
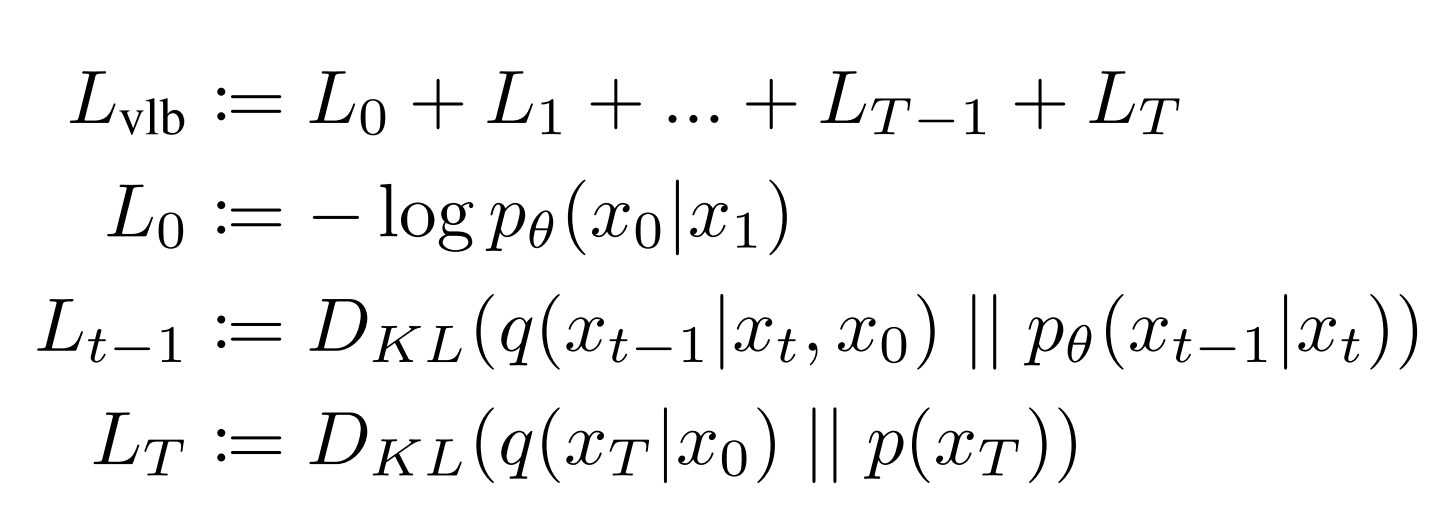
看上去较为复杂,原作者进行了如下化简:
- 抛弃 ,在实验中获得了更好的结果
- 抛弃 ,因为该项不涉及神经网络参数
于是便只需要考虑

其中
在实验中,作者发现固定 中的方差,对实验结果没有很大影响,即
进而可以推导得到
通过将 用 和 表达,可以将上面的式子转化为每步对噪声 进行优化(这里去掉了范数前的系数):
也即