理论的通俗解释
在 Diffusion Model 中,从简单的噪声分布 到数据分布 的过程,每个样本的转移路径是“弯曲的”,并不利于加速 backward 过程;相对应的,flow matching 则相当于假设已知每个样本的起点和终点,在两点之间划直线,“直接”转移过去。(有更严谨的理论推导,这里暂略)
为了严谨地描述这种“流动”,我们需要用到连续标准化流(Continuous Normalizing Flows, CNF)和常微分方程(ODE)。在连续时间 内,数据点 的轨迹可以用常微分方程描述:
这里 就是向量场,表示时间 、位置 处的流动速度和方向。Flow Matching 算法就是想要训练得到一个 来拟合 。一个直观的 loss 函数为:
问题在于,真实的 是极其复杂且难以计算的。因为在任何一个位置 ,转移方向是由成千上万个目标数据点共同拉扯决定的,需要对整个数据集进行积分。
Flow Matching 的作者证明了条件流匹配定理:
拟合复杂的宏观向量场,在数学上等价于拟合针对单个数据的简单条件向量场
也即,给定一个确定的起点噪声 和一个终点图像 ,定义一个时刻 的状态 :
对时间 求导,就得到了这条直线的速度(条件向量场 ):
实际训练神经网络时,使用的损失函数就变成了简单的均方误差:
上面让数据点走直线的特殊情况,在 Flow Matching 中被称为最优传输条件流匹配 (OT-CFM)。相比于传统的扩散模型(Score-based Models),Flow Matching 的优势在于:
- 路径更直 (Straight Paths): 数据到噪声的转换是笔直的,没有多余的绕弯
- 采样极快: 因为路径是直线的常微分方程,在生成(推理)阶段,我们可以使用步长极大的 ODE 求解器(如 Euler 法),只需极少的步数(比如几步到十几步)就能生成高质量数据,而不需要扩散模型那样的数百步
- 确定性: 整个生成过程是基于 ODE 的,给定一个初始噪声,生成的终点是唯一确定的
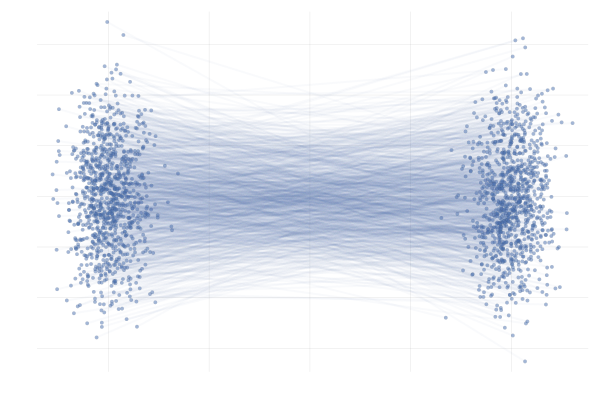
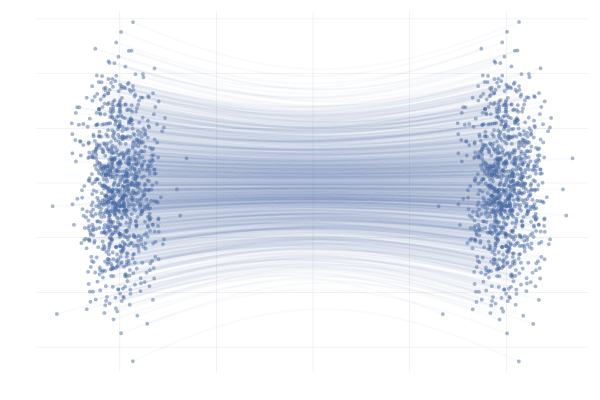
需要注意 和 的区别,如下两图:
 |  |
训练
训练的每一个 Step 包含以下 6 个步骤:
- 采样真实数据 ():从训练集中随机抽取一张真实的图片 。这代表了终点
- 采样纯噪声 ():从标准高斯分布中随机生成一个与图片维度相同的噪声 。这代表了起点
- 随机采样时间 ():在 之间随机抽取一个时间点
- 构建中间状态 ():根据最优传输(OT)的直线公式,计算在时刻 时,数据应该处于什么状态(加了多少噪):。(此时的 是一张既有噪声又有原图轮廓的混合图像)
- 计算目标速度 ():根据起点和终点,计算出这条直线上的标准转移速度:
- 神经网络预测与损失计算:把中间状态 和当前时间 输入给神经网络 (通常是一个 U-Net 或 DiT 架构),让它预测当前的风速:。然后,计算预测值 和真实目标 之间的 MSE Loss,并通过反向传播更新神经网络参数 :
推理
推理过程通常包含以下步骤:
- 初始化起点:从标准高斯分布中采样一个纯噪声 。设置初始时间
- 设定步长:决定你要分多少步走到终点。假设我们分 步生成(比如 或 ),那么每一步的时间跨度就是 。
- 循环迭代(从 到 ):在每一步迭代中执行以下操作:
- 观察风向: 把当前状态 和当前时间 喂给神经网络,获取速度预测:
- Euler 更新: 假设在极短的时间 内速度不变,沿着这个方向走一步,计算出下一个时刻的状态 :
- 时间推进:
- 输出结果:当 逐步增加到达 时,循环结束。此时的 就是模型最终生成的图像(或音频等数据)。